-
[Flink] Operator Chaining 알아보기Flink 2024. 3. 25. 06:07반응형
- 목차
들어가며.
이번 글에서는 Flink Operator Chaining 에 대해서 알아보려고 합니다.
Flink 는 여러 Operator 들을 조합하여 데이터 처리 어플리케이션을 구성합니다.
Flink Operator 의 예로 Filter, Map, Window, Join 등의 여러 Operator 들이 존재하며,
이들이 연결되어 하나의 어플리케이션을 만듭니다.
아래의 예시처럼 말이죠.
< Source -> Map -> Map -> Sink 로 구성된 Flink DataStream 의 그래프 >

Operator Chaining 은 여러 Operator 들을 하나의 Task 로 묶는 기법을 의미합니다.
아래 예시는 Source -> Map1 을 하나의 Task 로 묶고, Map2 -> Sink 를 하나의 Task 로 묶은 결과입니다.

이러한 방식으로 Flink Application 은 Operator Chaining 을 통해서 여러 성능 이득을 얻을 수 있는데요.
이번 글에서 Operator Chaining 과 관련된 예시들을 살펴보려고 합니다.
Operator, Task, SubTask 이란 ?
Operator, Task, SubTask 에 대해서 알아보도록 하겠습니다.
Operator.
Operator 는 Transformation 을 수행하는 기능적인 단위입니다.
Source, Map, Filter, Window 등과 같이 특정 기능을 수행하는 단위입니다.
그래서 Source -> Filter -> Map -> Window -> Sink 와 같이 구성된 Flink Application 은 5개의 Operator 들로 구성된다고 볼 수 있죠.
Task.
Task 는 TaskManager 에서 실행될 수 있는 실질적인 실행 단위입니다.
이 과정에서 Operator Chaining 이 적용되는데요.
Operator Chaining 이 적용된 여러 Operator 들은 하나의 Task 가 됩니다.
예를 들어, 아래와 같은 케이스에서 Source, Map1, Map2, Sink 와 같이 4개의 Operator 들이 존재하지만,
Task 는 2개가 존재합니다.
1번째 Task 는 source -> map1 으로 표현되는 Task 이구요.
2번째 Task 는 map2 -> sink 로 표현되는 Task 입니다.
Operator 들이 실행 계획에 따라 Task 로 변환됨으로써 TaskManager 에서 실행될 수 있습니다.
subTask.
subTask 는 Parallelism 에 따라서 Task 가 나뉘어진 결과입니다.
아래 이미지와 같이 하나의 Task 는 Parallelism 에 의해서 4개의 SubTask 로 분리됩니다.
그리고 이 SubTask 가 TaskManager 의 Slot 에서 실행되는 실질적인 실행 단위가 됩니다.

즉, subTask 갯수만큼 TaskManager 의 Slot 의 갯수가 요구됩니다.
Operator Chaining.
본격적으로 다양한 예시를 작성하기 이전에 샘플 코드부터 작성해보겠습니다.
package com.westlife.jobs; import org.apache.flink.api.common.functions.MapFunction; import org.apache.flink.configuration.ConfigConstants; import org.apache.flink.configuration.Configuration; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.source.SourceFunction; public class TestOperatorChaining { public static void main (String[] args) throws Exception { Configuration configuration = new Configuration(); configuration.setBoolean(ConfigConstants.LOCAL_START_WEBSERVER, true); configuration.setInteger(ConfigConstants.JOB_MANAGER_WEB_PORT_KEY, 8081); configuration.setInteger(ConfigConstants.TASK_MANAGER_NUM_TASK_SLOTS, 10); configuration.setInteger(ConfigConstants.LOCAL_NUMBER_TASK_MANAGER, 2); StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironment(1, configuration); env.setParallelism(1); DataStream<Integer> source = env.addSource(new CustomSource()).name("source"); DataStream<Integer> stream1 = source.map(new CpuIntensiveMapper("map1")).name("map1"); DataStream<Integer> stream2 = stream1.map(new CpuIntensiveMapper("map2")).name("map2").startNewChain(); stream2.print().name("print"); env.execute(); } private static class CustomSource implements SourceFunction<Integer> { @Override public void run(SourceContext<Integer> ctx) { int counter = 0; while (counter < 100) { ctx.collect(++counter); System.out.printf("$$$$$ source emit data %s , thread is %s \n", counter, Thread.currentThread().getId()); } } @Override public void cancel() { } } // While Loop 를 수행하면서 CPU 는 최대한 사용함. private static class CpuIntensiveMapper implements MapFunction<Integer, Integer> { private String name; protected CpuIntensiveMapper (String name) { this.name = name; } @Override public Integer map(Integer value) { long wait = 0; // While Loop 를 수행하면서 CPU 는 최대한 사용함. while (wait < 2000000000L) { wait++; } System.out.printf("##### %s is processing data %s , thread is %s \n", this.name, value, Thread.currentThread().getId()); return value; } } }위 샘플 코드는 Source 와 Mapper 를 구성합니다.
Source 는 단순히 1부터 100까지의 숫자를 생성합니다.
Mapper 는 CPUIntensiveMapper 라고 이름을 지어봤구요.
CPU 사용량이 많은 Mapper 를 While Loop 을 통해서 간단히 구성하였습니다.
disableOperatorChaining.
Flink 는 기본적으로 Operator Chaining 을 활성화합니다.
그래서 rebalance, shuffle, rescale 과 같이 명시적으로 Partitioning 을 적용하지 않는다면
아래와 같이 모든 Operator 들은 하나의 Task 로 묶입니다.

반면, disableOperatorChaining 을 통해서 모든 Operator 를 개별 Task 로 변형할 수 있습니다.
아래와 같이 env.disableOperatorChaining(); 를 통해서 Application 레벨에서 Operator Chaining 을 비활성화시킵니다.
public static void main (String[] args) throws Exception { Configuration configuration = new Configuration(); configuration.setBoolean(ConfigConstants.LOCAL_START_WEBSERVER, true); configuration.setInteger(ConfigConstants.JOB_MANAGER_WEB_PORT_KEY, 8081); configuration.setInteger(ConfigConstants.TASK_MANAGER_NUM_TASK_SLOTS, 10); configuration.setInteger(ConfigConstants.LOCAL_NUMBER_TASK_MANAGER, 2); StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironment(1, configuration); env.setParallelism(1); env.disableOperatorChaining(); DataStream<Integer> source = env.addSource(new CustomSource()).name("source"); DataStream<Integer> stream1 = source.map(new CpuIntensiveMapper("map1")).name("map1"); DataStream<Integer> stream2 = stream1.map(new CpuIntensiveMapper("map2")).name("map2"); stream2.print().name("print"); env.execute(); }DisableOperatorChaining 의 결과로써 만들어지는 Job Graph 는 아래와 같습니다.
모든 Operator 는 개별적으로 Task 로 변형됩니다.

startNewChain.
startNewChain 은 원하는 Operator 들만 하나의 Task 로 묶을 수 있는 기능을 제공합니다.
저는 보통 CPU 사용량이 많은 Operator 가 하나의 Core 를 온전히 점유할 수 있도록 다른 Task 로 분리하곤합니다.
Task1 (Source -> Map1) & Task2 (Map2 -> Sink).
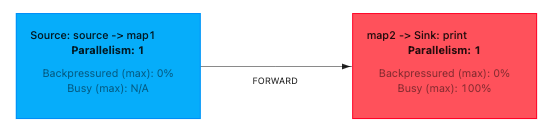
아래와 같이 startNewChain 을 적용함으로써 2개의 Task 로 분리됩니다.
public static void main (String[] args) throws Exception { Configuration configuration = new Configuration(); configuration.setBoolean(ConfigConstants.LOCAL_START_WEBSERVER, true); configuration.setInteger(ConfigConstants.JOB_MANAGER_WEB_PORT_KEY, 8081); configuration.setInteger(ConfigConstants.TASK_MANAGER_NUM_TASK_SLOTS, 10); configuration.setInteger(ConfigConstants.LOCAL_NUMBER_TASK_MANAGER, 2); StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironment(1, configuration); env.setParallelism(1); DataStream<Integer> source = env.addSource(new CustomSource()).name("source"); DataStream<Integer> stream1 = source.map(new CpuIntensiveMapper("map1")).name("map1"); DataStream<Integer> stream2 = stream1.map(new CpuIntensiveMapper("map2")).name("map2").startNewChain(); stream2.print().name("print"); env.execute(); }Task1 (Source) & Task2 (Map1 -> Map2) & Task3 (Sink).
이번에는 startNewChain 과 disableChaining 을 통해서 4개의 Operator 들을 3개의 Task 로 분리합니다.
disableChaining 을 Operator Chaining 에서 특정 Operator 을 제외시키는 기능을 제공합니다.
저의 경우는 Sink Operator 를 Map1 -> Map2 -> Sink Chaining 에서 제외시켰습니다.

public static void main (String[] args) throws Exception { Configuration configuration = new Configuration(); configuration.setBoolean(ConfigConstants.LOCAL_START_WEBSERVER, true); configuration.setInteger(ConfigConstants.JOB_MANAGER_WEB_PORT_KEY, 8081); configuration.setInteger(ConfigConstants.TASK_MANAGER_NUM_TASK_SLOTS, 10); configuration.setInteger(ConfigConstants.LOCAL_NUMBER_TASK_MANAGER, 2); StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironment(1, configuration); env.setParallelism(1); DataStream<Integer> source = env.addSource(new CustomSource()).name("source"); DataStream<Integer> stream1 = source.map(new CpuIntensiveMapper("map1")).name("map1").startNewChain(); DataStream<Integer> stream2 = stream1.map(new CpuIntensiveMapper("map2")).name("map2"); stream2.print().name("print").disableChaining(); env.execute(); }CPU Intensive Operator 는 어떻게 Chaining 하는 것이 효율적일까 ?
CPU Intensive Operator 를 효율적으로 처리하는 개인적인 경험을 공유하려고 합니다.
저는 CPU Intensive Operator 는 CPU 를 점유할 수 있는 기회를 최대한 많이 주어야한다고 생각합니다.
그래서 CPU Intensive Operator 를 하나의 Task 로 만들려고 하는 편입니다.
그리고 Task 가 Parallelism 에 의해서 subTask 로 분리된다고 말씀드렸죠 ?
이 SubTask 는 곧 Thread 를 의미합니다.
만약 연산이 많은 Operator 여러개가 하나의 Task 로 만들어진다면 이는 하나의 Thread 가 너무 많은 일을 수행하는 것과 같습니다.
결론을 먼저 말씀드리면 CPU Core 갯수가 허용하는 선에서 많은 수의 Task 를 만드는 것이 효율적입니다.
만약 CPU Core 갯수가 부족하다면 Source -> Mapper 또는 Mapper -> Sink 와 같이
연산이 적은 Operator 와 많은 Operator 를 하나의 Task 로 묶는 것이 효율적입니다.
1. DisableOperatorChaining.
모든 Operator 들을 개별 Task 로 분리하였습니다.
100개의 데이터를 처리하는데에 1분 8초가 소요됩니다.

2. 4 Operators & 1 Task.
모든 Operator 들을 하나의 Task 로 묶어보았습니다.
100개의 데이터를 처리하는데에 2분 9초가 소요됩니다.

3. 2 Operators & 2 Task.
CPU 연산이 큰 두 Mapper 를 별도의 Task 로 나누었고, 각 Task 에 Source 와 Sink 를 추가하였습니다.
100개의 데이터를 처리하는데에 1분 8초가 소요됩니다.
 반응형
반응형'Flink' 카테고리의 다른 글
[Flink] Operator Chain 알아보기 ( disableChaining, startNewChain ) (0) 2024.05.12 [Flink] Checkpoint Alignment 알아보기 (0) 2024.03.28 [Flink] Checkpoint Barrier Alignment 알아보기 (0) 2024.03.25 [Flink] Async IO Retry Strategy 알아보기 (0) 2024.03.23 [Flink] Async IO 알아보기 ( AsyncDataStream ) (0) 2024.03.23