-
[Kafka Producer] Data Loss 는 언제 발생할까 ?Kafka 2024. 1. 21. 07:30반응형

- 목차
함께 보면 좋은 글.
https://westlife0615.tistory.com/474
Docker 로 Kafka Cluster 구축해보기.
- 목차 소개. 저는 로컬 환경에서 카프카 관련 테스트를 진행하는 경우가 많이 생기더군요. 그래서 docker-compose 를 활용하여 Kafka, ZooKeeper 클러스터를 구축하는 내용을 작성하려고 합니다. docker-com
westlife0615.tistory.com
들어가며.
카프카 프로듀서는 비즈니스의 요구사항에 따라서 Data Loss 를 허용할 것인지, Data Duplication 을 허용할 것인지를 결정해야합니다.
Data Loss 를 허용하는 경우에는 서비스에서 데이터의 활용하는 속도를 늘리고, 시간을 감축시킬 수 있습니다.
웹사이트에서 발생하는 사용자들의 클릭 데이터, 스크롤 데이터를 수집하는 시스템을 구축한다고 가정해봅시다.
이 경우에 소량의 Data Loss 는 전체 비즈니스에 큰 영향을 끼치지 않습니다.
클릭 데이터를 기반으로 페이지의 HeatMap 을 만든다고 하더라도 큰 영향을 주진 않죠.
반면 구매나 환불같은 거래 데이터를 취급하는 경우에는 Data Loss 는 허용되지 않습니다.
아래의 사진들 중에서 첫번째 사진은 Click 데이터를 통해 만들어지는 결과물이고, 왼쪽 사진은 거래 데이터를 통해서 만들어지는 결과물입니다.
Data Loss 로 인해서 결제 데이터가 손상되면 큰 문제가 발생할 수 있겠죠 ?


출처 : https://capturly.com/documentation/what-is-click-heatmap/ & https://advicepay.helpscoutdocs.com/article/35-understanding-your-transfers-page 이번 글에서는 Kafka Producer 가 Data Loss 를 발생시킬 수 있는 설정들과 상황에서 대해서 알아보도록 하겠습니다.
Acks 가 0 인 경우.
대표적으로 Kafka Producer 가 Data Loss 를 야기하는 Producer 의 설정은 acks 가 0 인 경우입니다.
프로듀서와 브로커는 데이터를 생성하는 관점에서 서로 소통하게 됩니다.
프로듀서는 브로커에서 데이터의 생성을 요청하게 되고, 브로커는 생성이 완료된 데이터에 대한 응답을 제공합니다.
이 과정에서 acks 설정이 적용되는데요.
acks 가 0 인 경우는 아래의 이미지처럼 결과적으로 데이터의 생성이 실패하더라도
프로듀서와 브로커 간의 데이터 생성 흐름은 끊기지 않습니다.
이는 다른 표현으로 Fire-and-Forget 방식의 데이터 생성이라고 합니다.
그래서 Data Loss 에 관해서 안정적인 방식이 아닙니다.

반면 acks 가 1 또는 all 인 경우에는 아래의 이미지와 같이 프로듀서는 브로커에 의해서 데이터 생성에 실패함을 알게 됩니다.
그래서 적절한 Retry 를 수행하거나 Error Log 를 남겨 추후에 대응할 수 있습니다.

Acks 0 에 대한 코드 예시.
아래 코드예시는 acks 0 를 구현한 자바 코드입니다.
Producer 의 설정은 가능한 많은 양의 ProducerRecord 를 Batch Insert 하기 위하여
batch.size 와 buffer.memory 를 설정하였습니다.
Topic 의 이름은 bulk-topic 이고, Partition 과 Replication Factor 는 모두 1 로 설정하였습니다.
Kafka 클러스터는 https://westlife0615.tistory.com/474 페이지의 내용을 토대로 구축되었습니다.
Docker 로 Kafka Cluster 구축해보기.
- 목차 소개. 저는 로컬 환경에서 카프카 관련 테스트를 진행하는 경우가 많이 생기더군요. 그래서 docker-compose 를 활용하여 Kafka, ZooKeeper 클러스터를 구축하는 내용을 작성하려고 합니다. docker-com
westlife0615.tistory.com
package org.example.producers; import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.ProducerConfig; import org.apache.kafka.clients.producer.ProducerRecord; import org.apache.kafka.common.serialization.StringSerializer; import java.util.Properties; public class BulkInsert { public static void main (String[] args) { Properties properties = new Properties(); properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:29091,localhost:29092,localhost:29093"); properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 500 * 1024 * 1024); // 0.5gb properties.put(ProducerConfig.BATCH_SIZE_CONFIG, 6 * 1024 * 1024); // 6mb properties.put(ProducerConfig.LINGER_MS_CONFIG, 1 * 60 * 1000); // 1m properties.put(ProducerConfig.RETRIES_CONFIG, 100); properties.put(ProducerConfig.ACKS_CONFIG, "0"); String topic = "bulk-topic"; KafkaProducer<String, String> producer = new KafkaProducer<>(properties); for (long i = 1; i <= 1000000000; i++) { producer.send(new ProducerRecord<>(topic,null, i + "")); } producer.flush(); producer.close(); } }저는 Docker 환경에서 테스트를 진행하고 있구요.
kafka2 이라는 브로커에서 bulk-topic 의 Leader Replica 로 설정되어서 5초, 30초 주기로 브로커를 restart 시켰습니다.
while true; do docker stop kafka2; sleep 5; docker start kafka2; sleep 30; done;Leader Replica 가 불안정한 상태이기 때문에 필연적으로 Producer 의 데이터 생성에 영향을 끼치도록 상황을 설계하였구요.
아래 사진처럼 15747508 과 16111474 Offset 사이에 Data Loss 가 발생하였습니다.

반면 Acks 가 1 또는 -1 인 경우.
Acks 가 1 또는 -1 인 경우에는 데이터의 중복이 발생할 수 있습니다.
아래와 같은 상황이 대표적인 상황인데요.
불안정한 브로커는 정상적으로 Record 를 저장하였지만, 프로듀서에게 Acknowledgement 를 응답하는 과정에서 종료되게 됩니다.
그 상황에서 프로듀서는 자신이 데이터 생성에 성공하지 못했다고 판단하여 새롭게 Retry 를 시도합니다.
결과적으로 데이터의 중복이 발생하죠.
< Acknowledgement 실패 >

< Retry & 데이터 중복 발생 >

아래 코드 예시는 bulk-topic- 2 토픽에 Acks 1 인 설정으로 데이터를 생성하는 자바 코드입니다.
package org.example.producers; import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.ProducerConfig; import org.apache.kafka.clients.producer.ProducerRecord; import org.apache.kafka.common.serialization.StringSerializer; import java.util.Properties; public class BulkInsert { public static void main (String[] args) { Properties properties = new Properties(); properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:29091,localhost:29092,localhost:29093"); properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 500 * 1024 * 1024); // 0.5gb properties.put(ProducerConfig.BATCH_SIZE_CONFIG, 6 * 1024 * 1024); // 6mb properties.put(ProducerConfig.LINGER_MS_CONFIG, 1 * 60 * 1000); // 1m properties.put(ProducerConfig.RETRIES_CONFIG, 100); properties.put(ProducerConfig.ACKS_CONFIG, "1"); String topic = "bulk-topic-2"; KafkaProducer<String, String> producer = new KafkaProducer<>(properties); for (long i = 1; i <= 1000000000; i++) { producer.send(new ProducerRecord<>(topic,null, i + "")); } producer.flush(); producer.close(); } }그리고 아래의 이미지처럼 데이터의 중복이 발생하게 됩니다.

unclean.leader.election.enable True 인 경우.
unclean.leader.election.enable 설정은 Leader Replica 가 종료되고 Follower Replica 가 새로운 Leader 가 되는 과정에서
Replication Lag 이 있는 Follower Replica 가 Leader 로 승격되도록 설정하는 옵션입니다.
요약하면 데이터 복제가 덜 된 상태의 Follower Replica 가 새로운 Leader 되는 경우에 데이터 손실이 발생하게 됩니다.
아래 이미지와 같이 Leader Replica 인 Broker 2 와 Follower Replica 인 Broker 1, Broker 3 가 존재합니다.
Follower Replica 는 Leader Replica 의 Log 상태에 맞추어 Replication 을 수행하게 되는데요.
아래 상태처럼 복제된 Record 와 원본 Record 가 다른 상태를 unclean 이라고 표현하구요.
unclean Follower Replica 가 새로운 Leader Replica 가 되는 것은 unclean.leader.election 이라고 합니다.
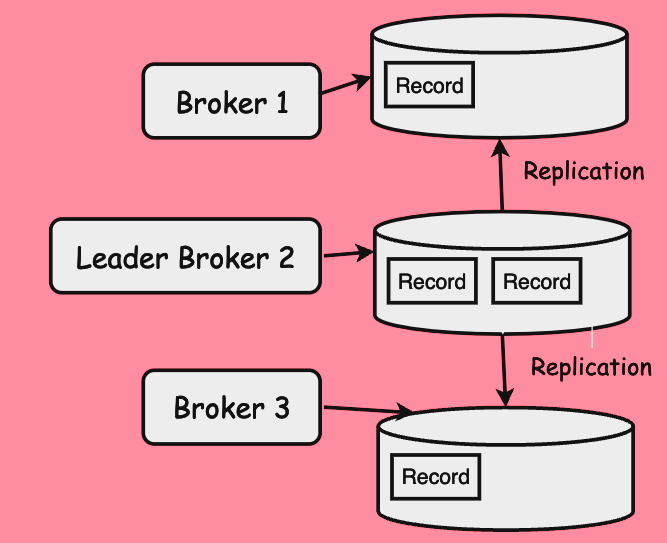
이 경우에는 필연적으로 Data Loss 가 발생합니다.
unclean.leader.election 와 Data Loss 를 재현하기 위한 코드 예시.
새로운 토픽을 생성하였습니다.
토픽의 이름은 unclean-leader 이고, Partition 은 1개, Replication Factor 는 3으로 설정하였습니다.
package org.example.producers; import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.ProducerConfig; import org.apache.kafka.clients.producer.ProducerRecord; import org.apache.kafka.common.serialization.StringSerializer; import java.util.Properties; public class BulkInsert { public static void main (String[] args) { Properties properties = new Properties(); properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:29091,localhost:29092,localhost:29093"); properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 500 * 1024 * 1024); // 0.5gb properties.put(ProducerConfig.BATCH_SIZE_CONFIG, 6 * 1024 * 1024); // 6mb properties.put(ProducerConfig.LINGER_MS_CONFIG, 1 * 60 * 1000); // 1m properties.put(ProducerConfig.RETRIES_CONFIG, 100); properties.put(ProducerConfig.ACKS_CONFIG, "1"); String topic = "unclean-leader"; KafkaProducer<String, String> producer = new KafkaProducer<>(properties); for (long i = 1; i <= 1000000000; i++) { producer.send(new ProducerRecord<>(topic,null, i + "")); } producer.flush(); producer.close(); } }아래의 명령어는 2초 주기로 브로커들을 재시작시키는 명령어입니다.
카프카 브로커들을 불안정하기 만들기 위해서 실행하는 코드입니다.
그리고 unclean leader election 을 유도합니다.
while true; do docker stop kafka1; sleep 2; \ docker start kafka1; docker stop kafka2; sleep 2; \ docker start kafka2; docker stop kafka2; sleep 2; docker start kafka3; done;아래 이미지는 Kafdrop 에서 캡쳐한 데이터의 상태입니다.
레코드의 값이 1191122 ~ 1948096 인 레코드들이 모두 손실되었음을 확인할 수 있습니다.

마치며.
위 케이스들이 Data Loss 를 유발할 수 있는 상황들입니다.
사실상 Kafka Producer 만을 통해서 데이터 정합성의 목표를 달성하기란 쉽지 않습니다.
저의 경우에는 At-Least Once 방식으로 데이터의 중복이 발생할지언정 데이터의 손실을 방지하는 방향으로 목표를 세웁니다.
데이터의 중복은 Consumer 레벨에서 적절히 처리할 수 있으니까요.
여기까지 읽어주셔서 감사합니다.
반응형'Kafka' 카테고리의 다른 글
[Kafka] Kafka Rebalance Protocol 알아보기 ( JoinGroup, LeaveGroup ) (0) 2024.02.04 [Kafka] API Version 알아보기 ( Protocol ) (0) 2024.01.31 Kafka Controller 알아보기 (0) 2024.01.17 [Kafka] Replication 의 시간은 얼마나 걸릴까 ? ( kafka-reassign-partitions ) (0) 2024.01.14 [Kafka Consumer] Exactly-Once 구현하기 (0) 2024.01.13