-
RocksDB Architecture 알아보기 (LSM-tree)Database/RocksDB 2024. 1. 10. 07:45반응형

- 목차
관련된 글.
https://westlife0615.tistory.com/566
RocksDB Architecture 알아보기 (LSM-tree)
- 목차 들어가며. RocksDB 는 LSM-Tree 형식의 구조를 취합니다. LSM-Tree 를 설명하기 위해서 MemTable, SSTable, WAL Log, Compaction 등의 배경지식이 필요한데요. 이번 글에서 RocksDB 를 구성하는 요소들에 대해
westlife0615.tistory.com
https://westlife0615.tistory.com/567
RocksDB Column Family 알아보기
- 목차 들어가며. RocksDB 의 Column Family 는 SQL 의 Table, NoSQL 의 Collection 과 유사합니다. 즉, Key-Value Pair 들을 저장하는 논리적인 단위입니다. 즉, RocksDB 의 데이터베이스는 Column Family 라는 단위로 데이
westlife0615.tistory.com
들어가며.
RocksDB 는 LSM-Tree 형식의 구조를 취합니다.
LSM-Tree 를 설명하기 위해서 MemTable, SSTable, WAL Log, Compaction 등의 배경지식이 필요한데요.
이번 글에서 RocksDB 를 구성하는 요소들에 대해서 자세히 알아보는 시간을 가지려고 합니다.
MemTable.
MemTable 은 이름에서 알 수 있듯이, LSM Tree 구조 상에서 데이터를 취급하는 메모리의 영역입니다.
데이터 저장 측면에서 메모리가 수행하는 역할은 크게 두가지입니다.
- Cache (캐시)
- Buffer (버퍼)
캐시로써 MemTable 은 데이터의 조회 속도를 빠르게 합니다.
조회 빈도가 높은 데이터를 메모리 영역에 적재함으로써 데이터 조회 시에 Disk IO 를 최소화합니다.
이러한 관점에서 데이터의 조회 속도를 향상시킵니다.
그리고 버퍼로써의 MemTable 은 데이터의 생성 속도를 향상시킵니다.
Client 가 데이터를 생성하는 요청의 속도는 컴퓨팅 파워를 사용하기 때문에 Disk 에 데이터를 생성하는 속도보다 월등히 빠릅니다.
그래서 메모리 영역에 데이터를 임시적으로 저장하는 버퍼를 두어 Client 가 느끼는 생성의 시간을 감소시킵니다.
아래 이미지처럼 Client 는 Memory Buffer 에 데이터가 쌓이는 시점까지 기다리게 됩니다.
이는 영구적인 데이터의 저장은 아니지만, LSM Tree 는 WAL Log, Checkpoint 등의 방식으로
데이터가 손실되지 않는 방법을 가집니다.
이러한 관점에서 MemTable 은 통해서 데이터의 생성 시간을 단축합니다.

Memory Write Buffer Active MemTable & Read-Only MemTable.
MemTable 은 데이터 생성을 위한 버퍼로써 클라이언트의 데이터 생성 로그를 저장합니다.
꾸준히 클라이언트의 데이터 생성이 이어지다가 끝내 MemTable 의 버퍼 사이즈의 한계에 도달하게 되는 시점이 옵니다.
이때, MemTable 은 Disk 로의 Flush 를 위한 준비를 하는데요.
지금까지 클라이언트의 생성 로그를 수집한 MemTable 은 Read-Only MemTable 이 되어 Disk Flush 작업을 수행하게 됩니다.
그리고 새로운 Active MemTable 이 생성되고, Active MemTable 은 또다시 데이터 생성 로그를 저장합니다.
RocksDB 의 max_buffer_bytes 설정을 통해서 Write Buffer 인 MemTable 의 용량 한계치를 설정할 수 있으며,
Active MemTable 의 용량이 max_buffer_bytes 의 값에 도달하게 되면,
Active MemTable 은 ReadOnly MemTable 이 되어 Flush 가 됩니다.
SSTable.
SSTable 은 Sorted String Table 의 약자입니다.
이는 SSTable 이 데이터와 파일들을 관리하는 방법에서 이러한 이름이 파생되었는데요.
SSTable 을 데이터 관리 관점과 영구 저장소의 관점에서 각각 살펴보도록 하겠습니다.
Sorted String 이란 무엇인가?
먼저 SSTable 은 MemTable 의 데이터들이 Flush 되어 저장되는 On-Disk 영역의 파일입니다.
.sst 확장자를 가지는 파일인데요.
단순히 생각해서 클라이언트에 의해서 Write 된 Key-Value Pair 들이 저장되어 있다고 생각하시면 됩니다.
아래 이미지는 Sorted String 을 표현하기 위해서 제가 만든 간단한 SSTable 파일인데요.
a, ab, b, bz, c, d 인 Key 들이 순서대로 정렬되어 있습니다.
이렇게 정렬되어 있기 때문에 Binary Search 알고리즘과 같은 방식으로 효율적인 탐색이 가능해집니다.

그리고 Sorted String Table 의 다른 중요한 점은 SSTable 이 Key Range 에 의한 Sharding 이 된다는 점입니다.
아래 이미지처럼 SSTable 은 단 하나로 구성되는 것이 아니라 여러 SSTable 들이 존재합니다.
그리고 각 SSTable 은 데이터를 저장하는 Key 의 범위가 정해지는데요.
a 부터 z 까지의 데이터를 3개의 범위로 나누어 저장을 하게되고 더 효율적인 데이터 탐색이 가능해집니다.
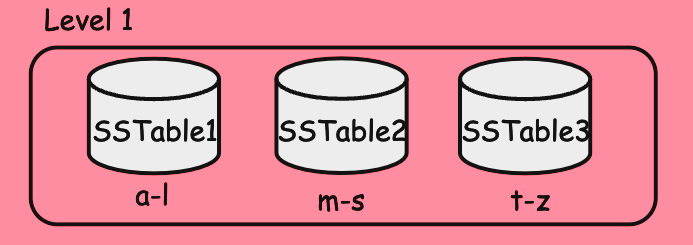
SSTable 파일들은 어떻게 관리되는가 ?
SSTable 은 RocksDB 의 Compaction 에 의해서 삭제되고 생성되고 병합되는 과정을 반복합니다.
Compaction 이 무엇이고, 왜 삭제&생성&병합을 이해하기 위해서 Level 이라는 개념이 필요합니다.
RocksDB 는 Level 0 부터 시작하여 Level N 까지 Compaction 의 정도를 구분짓는데요.
MemTable 이 가득 차서 데이터들이 Flush 된다면 이 데이터들은 Level 0 의 SSTable 이 됩니다.
이 과정에서 SSTable 이 생성되죠.
그리고 Level 0 의 SSTable 들이 많이 생겨서 한계치에 다다르게 되면, Level 1 의 SSTable 이 만들어집니다.
이 과정에서 Level 0 의 SSTable 들이 삭제됩니다.
이러한 Compaction 이 반복된다면, Key Range 가 겹치는 두 SSTable 은 서로 병합되게 되는데,
이 과정에서 SSTable 이 서로 합쳐집니다.
자세한 내용은 Leveled Compaction 에 대해서 설명한 아래의 링크를 참조해주시면 좋을 것 같습니다.
https://westlife0615.tistory.com/568
Write-Ahead Log.
Write-Ahead Log 는 RocksDB 의 Recovery 를 위해서 사용됩니다.
RocksDB 가 수행하는 데이터의 실질적인 Read/Write 는 MemTable 과 SSTable 과 관련됩니다.
수 많은 데이터베이스가 그렇듯, Disk 로의 즉각적인 Write 작업은 발생하지 않습니다.
Disk IO 는 많은 시간을 소요하는 과정이기에 Memory 영역의 Write Buffer 를 두어 이를 해결합니다.
그래서 데이터를 저장하는 클라이언트가 보기에는 되게 빠른 속도로 데이터가 저장됨을 느끼겠지만,
실제 데이터는 RocksDB 의 메모리에 머물고 있죠.
그리고 이는 Fault-Tolerance 측면에서 문제가 있죠.
따라서 MySQL 의 Redo Log, Hadoop 의 Edit Log 등과 같이 Write-Ahead Log 를 두어,
모든 Transaction Log 를 기록하게 됩니다.
그래서 RocksDB 가 다운되더라도 WAL Log 의 기록을 통해서 휘발된 데이터들을 복구할 수 있습니다.
아래 이미지는 Write-Ahead Log 와 MemTable 에 쓰기 작업이 수행되는 과정입니다.
Write-Ahead Log 와 MemTable 의 Write Log 가 같이 기록되기 때문에 데이터의 휘발과 관련된 문제를 해결할 수 있습니다.
 반응형
반응형'Database > RocksDB' 카테고리의 다른 글
RocksDB Leveled Compaction 알아보기 (0) 2024.01.10 RocksDB WAL (Write-Ahead Log) 알아보기 (2) 2024.01.10 RocksDB Column Family 알아보기 (0) 2024.01.10