-
[Kafka] Key Partitioner 알아보기Kafka 2024. 1. 5. 06:12반응형

- 목차
함께 보면 좋은 글.
https://westlife0615.tistory.com/886
[Kafka] Adaptive Partitioning 코드로 살펴보는 내부 동작 원리
- 목차 들어가며.Kafka의 Adaptive Partitioning 은 Kafka 프로듀서가 데이터를 효율적으로 분배하기 위해 동적으로 파티션 할당 전략을 조정하는 기법입니다.3.x.x 대 버전의 Kafka Client Module 에서는 기본
westlife0615.tistory.com
소개.
Partitioner 는 Producer 가 생성한 Record 를 어떤 Partition 에 저장할지 결정하는 Producer 의 기능입니다.
보통 하나의 Topic 은 여러개의 Partition 들로 구성되고, Record 들은 골고루 Partition 으로 분배됩니다.
이렇게 Partitioner 는 Record 들을 Topic 의 Partition 으로 분배하는 역할을 수행합니다.
레코드를 분배하는데에 사용되는 정보가 Record 의 Key 입니다.
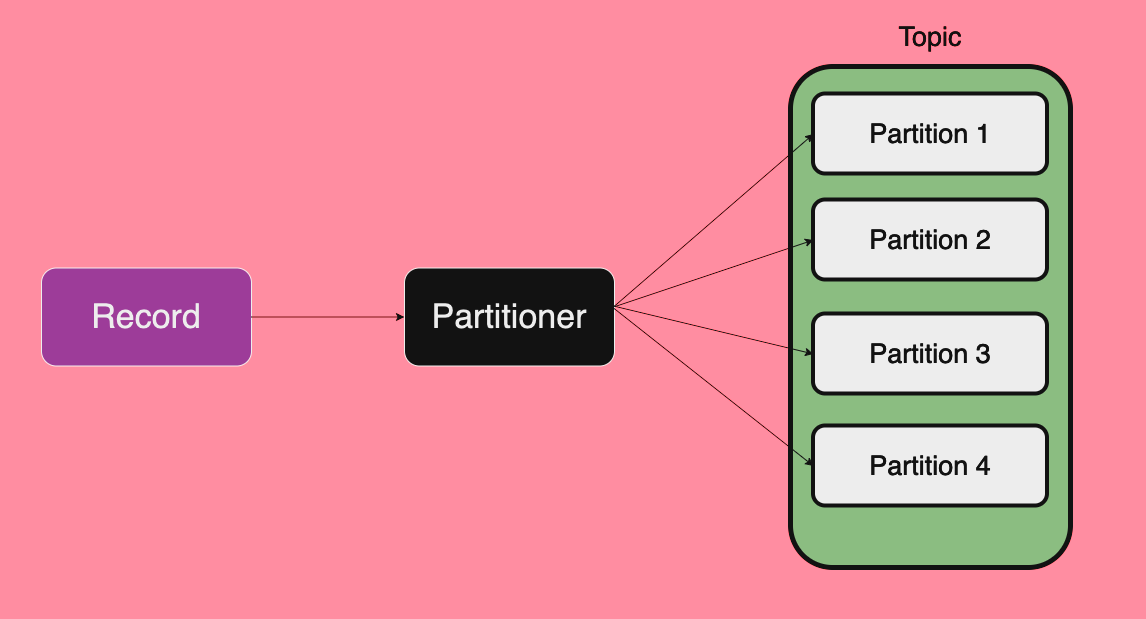
Kafka Producer Partitioner 그리고 Record 는 key, value, timestamp, header 등의 구성요소들로 구성됩니다.
그 중에서 key 에 해당하는 정보를 기반으로 Record 가 저장된 Partition 을 선택합니다.
어떠한 방식으로 Record 가 저장될 Partition 을 결정하는지는 Partitioner 의 역할입니다.
일반적으로 Round-Robin 방식이 사용되며, 사용자에 의해서 Customizing 될 수 있습니다.
Default Partitioner.
Kafka Producer 생성 시에 기본적으로 적용되는 Partitioner 의 종류입니다.
Java 기준으로 보았을 때, org.apache.kafka.clients.producer.internals.DefaultPartitioner 에 해당하는 클래스가 사용되구요.
동작 방식은 Record 의 key 를 Hashing 하여 도출되는 결과값을 사용합니다.
그래서 동일한 Record Key 에 대하여 동일한 Partition 에 저장될 수 있도록 합니다.
그리고 Record 의 Key 가 null 인 케이스는 Round-Robin 방식이 적용됩니다.
아래 함수가 DefaultPartitioner.java 파일에서 발췌한 내용인데요.
MurmurHash 를 적용하여 Hashing 결과값과 Partition 의 갯수를 사용하여 Partitioning 을 시도합니다.
그리고 keyBytes == null 인 케이스는 내부적으로 Round-Robin 방식이 적용됩니다.
< DefaultPartitioner.java >
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster, int numPartitions) { if (keyBytes == null) { return stickyPartitionCache.partition(topic, cluster); } // hash the keyBytes to choose a partition return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions; }Key 가 Null 인 경우.
Record 의 key 가 null 인 경우, DefaultPartitioner 는 Round-Robin 방식으로 Partition 을 결정한다고 말씀드렸습니다.
아래 자바 코드는 Record 의 key 가 null 인 경우의 Producer 코드이구요.
결과를 한번 확인해보겠습니다.
public static void main (String[] args) { Properties properties = new Properties(); properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:29092,localhost:29092,localhost:29092"); properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer"); properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer"); KafkaProducer<String, String> producer = new KafkaProducer<>(properties); String topic = "key_is_null"; String key = null; String value = "value"; long counter = 0; while (counter < 1000000) { ProducerRecord<String, String> record = new ProducerRecord(topic, key, value); producer.send(record); counter++; } }
topic and partition round-robin "key_is_null" Topic 은 3개의 Partition 들로 구성됩니다.
그리고 Record 의 key 가 null 이며, DefaultPartitioner 를 사용하기 때문에 위 이미지처럼
Record 들은 고르게 Partition 들로 분배되어 저장됩니다.
key 가 Null 이 아닌 경우.
이번에는 Record 의 key 가 null 이 아닌 경우입니다.
저는 key == 1 로 설정하여 Producer 코드를 실행해보았습니다.
아래 이미지 예시처럼 "key_is_not_null" Topic 은 하나의 파티션에 모든 Record 들이 저장됩니다.
"1" 이라는 Key 는 DefaultPartitioner 에 의해서 항상 동일한 Partition 이 결정되기 때문입니다.
public static void main (String[] args) { Properties properties = new Properties(); properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:29092,localhost:29092,localhost:29092"); properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer"); properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer"); KafkaProducer<String, String> producer = new KafkaProducer<>(properties); String topic = "key_is_not_null"; String key = "1"; String value = "value"; long counter = 0; while (counter < 1000000) { ProducerRecord<String, String> record = new ProducerRecord(topic, key, value); producer.send(record); counter++; } }
Custom Partitioner.
사용자에 의해서 Custom Partitioner 를 지정할 수 있습니다.
지정하는 방법은 아래와 같습니다.
1. Custom Partitioner Class 를 구현합니다.
Custom Partitioner 는 org.apache.kafka.clients.producer.Partitioner 를 implements 해야합니다.
package com.westlife.kafka.components.partitioner; import org.apache.kafka.clients.producer.Partitioner; import org.apache.kafka.common.Cluster; import org.apache.kafka.common.InvalidRecordException; import org.apache.kafka.common.PartitionInfo; import java.util.List; import java.util.Map; import java.util.Random; public class CustomPartitioner implements Partitioner { @Override public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) { List<PartitionInfo> partitions = cluster.partitionsForTopic(topic); if (key == null) { throw new InvalidRecordException("Key cannot be null for custom partitioner"); } int numPartitions = partitions.size(); return ((int)(new Random().nextDouble() * numPartitions)); } @Override public void close() { } @Override public void configure(Map<String, ?> configs) { } }2. Producer 의 설정에 Custom Partitioner 를 등록합니다.
아래와 같이 생성한 Custom Partitioner class 의 Fully Qualified Name 을 등록해야합니다.
public static void main (String[] args) { Properties properties = new Properties(); properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:29092,localhost:29092,localhost:29092"); properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer"); properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer"); properties.setProperty(ProducerConfig.PARTITIONER_CLASS_CONFIG, "com.westlife.kafka.components.partitioner.CustomPartitioner"); KafkaProducer<String, String> producer = new KafkaProducer<>(properties); String topic = "key_is_not_null"; String key = null; String value = "value"; long counter = 0; while (counter < 1000000) { ProducerRecord<String, String> record = new ProducerRecord(topic, key, value); producer.send(record); counter++; } }반응형'Kafka' 카테고리의 다른 글
[Kafka-Connect] S3 Sink Connector 따라해보기 1 (0) 2024.01.08 [Kafka-Streams] KStream 알아보기 (0) 2024.01.06 [Kafka] ProducerInterceptors 알아보기 (0) 2024.01.05 [Kafka] Partition Ownership 알아보기 (0) 2024.01.05 [Kafka] Log Index File 알아보기 (0) 2024.01.03