-
[Pandas] stack 사용하여 Pivot Table 만들기 ( pivot_table )Python 2023. 7. 10. 11:13728x90반응형
- 목차
키워드.
- pandas
- stack, unstack
- pivot
들어가며.
이번 글에서는 Pandas DataFrame 의 stack, unstack 함수를 활용하여 Pivot Table 을 생성하는 방법에 대해서 설명하려고 합니다.
간단히 stack 과 unstack 에 관한 설명과 더불어 pivot table 을 생성하는 응용 과정에 대해 이야기하도록 하겠습니다.
stack.
Pandas 의 stack 함수는 모든 Column 들을 index 위치로 변경할 수 있습니다.
먼저 간단한 예시를 통해서 stack 의 쓰임새를 보여드리겠습니다.
stack 함수를 활용할 DataFrame 을 하나 생성하구요.import pandas as pd names = ["Andy", "Bob", "Chris", "Daniel"] cities = ["Seoul", "Seoul", "Seoul", "NewYork"] df = pd.DataFrame({"name" : names, "city" : cities})
Column 들을 stack 을 통해 index 위치로 변경합니다.
아래의 결과와 같이 기존의 Column 이었던 "name" 과 "city" 칼럼이 Index 의 위치로 옮겨집니다.df.stack()
stack 함수가 적용된 시점부터 index 는 MultiIndex 타입이 됩니다.
즉, 2개의 Index 를 가지게 되죠.df.stack().index
그리고 모든 칼럼들이 Index 의 위치로 옮겨졌기 때문에 더 이상 DataFrame 이 아닌 Series 으로 변환됩니다.print(type(df.stack())) >> <class 'pandas.core.series.Series'>
unstack.
unstack 은 stack 의 반대 역할을 수행합니다.
index 를 column 의 위치로 변경합니다.stacked_df = df.stack()
unstack 함수를 사용하여 원래 DataFrame 으로 복구가 가능합니다.stacked_df.unstack()
level.
stack 과 unstack 은 level 이라는 인자를 사용할 수 있습니다.
위에서 확인할 수 있듯이, stack 함수를 사용하게 되면, index 는 MultiIndex 로 변환됩니다.
이때 level 개념을 통해 MultiIndex 중에서 하나의 Index 를 Column 으로 변환이 가능합니다.
"level=0" 와 같이 level 을 0 으로 설정하면 기존의 RangeIndex 가 Column 으로 자리를 옮깁니다.stacked_df.unstack(level=0)
"level=1" 와 같이 level 을 1 으로 설정하면 name 과 city 가 Column 자리로 옮겨집니다.stacked_df.unstack(level=1)
Pivot Table 만들기.
DataFrame 을 Pivot Table 으로 변경하기 위해서 groupby, unstack 두가지를 사용할 예정입니다.
스마트폰 브랜드와 사용자 간의 관계를 표현하기 위해 간단한 DataFrame 을 생성합니다.import pandas as pd names = ["Andy", "Bob", "Chris", "Daniel", "Emma", "Frank", "Gareth"] phones = ["Apple", "Samsung", "Apple", "Huawei", "Xiaomi", "Apple", "Samsung"] df = pd.DataFrame({"name" : names, "phone" : phones})
assign.
먼저 assign 함수를 1 로 구성된 list 를 "count" 칼럼에 추가합니다.
df.assign(count=[1] * len(df))
groupby.
그리고 groupby 와 agg 함수를 사용하여 스마트폰 사용자와 브랜드 별 관계를 계산합니다.
아래 데이터를 살펴보면 Andy 는 Apple 스마트폰 1개를 사용 중이고, Bob 은 Samsung 스마트폰 1개를 사용합니다.df.assign(count=[1] * len(df)).groupby(["name", "phone"]).agg({"count": "sum"})
위에서 groupby 의 인자로써 2개의 Column 들을 사용하였는데요.
이러한 경우에 index 는 MultiIndex 로 변경됩니다.
unstack.
그리고 unstack 함수를 사용하여 "phone" index 를 Column 위치로 옮겨줍니다.
그럼 아래와 같은 상태가 됩니다.(df.assign(count=[1] * len(df)) .groupby(["name", "phone"]) .agg({"count": "sum"}) .unstack(level=1) )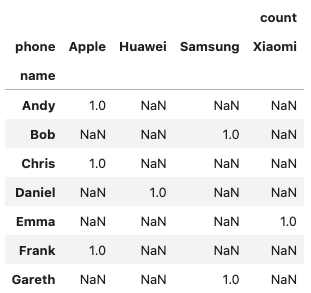
그리고 fillna 를 적용하여 nan 값을 0 으로 변경하고, droplevel 함수를 통해서 MultiIndex 를 하나의 Index 로 변경합니다.(df.assign(count=[1] * len(df)) .groupby(["name", "phone"]) .agg({"count": "sum"}) .unstack() .fillna(0) .droplevel(0, axis=1))
위와 같이 stack 함수를 통해서 두 칼럼들의 상호 관계를 Pivot Table 형식으로 표현할 수 있게 됩니다.pivot_table 함수 사용하기.
사실 위와 같은 절차를 적용하는 것보다 pivot_table 함수를 활용하는 것이 훨씬 직관적이고 간편합니다.
아래와 같은 name 과 phone 칼럼을 가지는 DataFrame 이 존재하고,
import pandas as pd names = ["Andy", "Bob", "Chris", "Daniel", "Emma", "Frank", "Gareth"] phones = ["Apple", "Samsung", "Apple", "Huawei", "Xiaomi", "Apple", "Samsung"] df = pd.DataFrame({"name" : names, "phone" : phones})
새로운 "count" 칼럼을 추가합니다.
df.assign(count=[1] * len(df))
그 이후에 아래와 같이 pivot_table 함수를 적용할 수 있습니다.
name_phone_count_df = df.assign(count=[1] * len(df)) name_phone_count_df.pivot_table(index="name", columns="phone", values="count") 반응형
반응형'Python' 카테고리의 다른 글
[Pandas] rolling function 알아보기 (0) 2023.12.03 [numpy] axis 사용법 ( min, max, sum ) 알아보기 (0) 2023.09.06 [pandas] get_dummies 알아보기 ( One Hot Encoding ) (0) 2023.02.06 Matplotlib Scatter 사용법 알아보기 (0) 2023.01.21 [pandas] to_datetime 함수 알아보기 (0) 2022.12.20