-
RabbitMQ 에 대해서BigData 2023. 4. 9. 19:51반응형
개요
RabbitMQ 는 흔히 말하는 메시지 브로커의 한 종류입니다.
메시지 브로커는 여러 서비스 사이에서 메시지를 중재하는 역할을 수행하는데요.
메시지라고 불리는 의미있는 데이터를 생산자로부터 소비자로 전송해주는 역할을 수행합니다.
그리고 단순한 메시지 전송을 넘어서 브로드캐스팅이라던지, 특정 기간 동안 메시지를 보관해준다던지하는 추가적인 역할 또한 수행합니다.
메시지란
RabbitMQ 에서 메시지란 단순히 의미있는 정보 (데이터) 를 의미합니다.
단순히 읽을 수 있는 정보를 담은 text message 일 수 있고,
원격의 서버나 프로세스에게 명령어를 전달하는 용도일 수 있습니다.
IoT 기기들에서 발생하는 센서 정보들 또는 여러 웹 로그와 같이
일일이 다루기 힘든 많은 양의 데이터들이 RabbitMQ 에서 다뤄질 수 있고,
Spring Cloud 같은 micro-service 간의 소통을 위한 용도로 사용될 수 있습니다.
AMQP
Advanced Messaging Queue Protocol 의 약자입니다.
Messaging Queue 의 표준 프로토콜이며, RabbitMQ 가 AMQP 의 대표적인 제품입니다.
AMQP 는 메시지 브로커에서 구현해야할 행동 양식이 정의되어 있으며,
구체적으로 Exchange, Binding, Queue 의 상호 관계가 주를 이룹니다.
Application-Layer 에서 동작하는 응용 계층의 프로토콜로써 메시지는 헤더와 바디에 해당 규격을 준수해야합니다.
예를 들어, Exchange 가 이해할 수 있는 Routing Key 가 메시지의 헤더에 포함되어야합니다.
Connection
RabbitMQ 서버와 RabbitMQ 클라이언트 사이의 연결입니다.
메시지 생산자 또는 소비자가 메시지 브로커와 맺는 연결입니다.
TCP 기반의 연결로 클라이언트와 서버의 물리적인 연결을 의미합니다.
AMQP 와 Channel 은 Application-Level 의 개념과 존재이므로 Transport-Level 인 Connection 위에서 동작하게 됩니다.
여러 TCP 연결과 유사하게 Long-Lived 정책을 고수하며,
패킷 형태의 데이터를 전송합니다.
Channel
AMQP 에서 활용되는 논리적인 (또는 가상의 ) 연결입니다.
Connection 이 물리적인 연결이라면, Channel 은 그 물리적 환경 위에서 관리되는 가상의 연결인데요.
프로세스와 쓰레드의 관계와 유사합니다.
하나의 프로세스 위에서 여러 쓰레드들이 스케줄링에 의해 동시 진행되는 것처럼 느껴지듯이,
하나의 물리적인 Connection 위에서 여러 Channel 들이 관리됩니다.
이를 달리 표현하면,
Connection 없이 Channel 은 존재할 수 없으며, Channel 은 Connection 의 범위에 제한됩니다.
그래서 Connection 이 종료가 되면 자동적으로 Channel 또한 사용할 수 없습니다.
Channel 은 어플리케이션에서 발생하는 여러 예외 상황으로부터 클라이언트와 서버 간의 연결을 보호하기 위하여,
여러 Channel 을 사용하는 방식이 권장됩니다. (쓰레드 당 하나의 Channel 이 사용되는 것이 권장됩니다. )
그리고 멀티 쓰레드 환경에서 리소스 접근을 위한 경쟁도 피할 수 있게 됩니다.
Exchange
Exchange 의 역할은 메시지의 라우팅입니다.
Producer 로부터 전달받은 메시지를 적절한 Queue 로 라우팅하는 역할을 수행합니다.
Queue
Queue 는 메시지-큐 시스템에서 실질적인 저장소의 역할을 담당합니다.
Exchange 단계로부터 전달된 메시지를 메모리 또는 디스크에 저장합니다.
예시
docker 로 rabbitmq 를 실행합니다.
docker run -d --name rabbitmq -p 5672:5672 --restart=unless-stopped \ -e RABBITMQ_DEFAULT_USER=username \ -e RABBITMQ_DEFAULT_PASS=password \ rabbitmq:managementproduce.py
import pika if __name__ == "__main__": // 1. Connection 을 생성합니다. credentials = pika.PlainCredentials('username', 'password') parameters = pika.ConnectionParameters( 'localhost', credentials=credentials, heartbeat=5) connection = pika.BlockingConnection(parameters) // 2. Channel 을 생성합니다. channel = connection.channel() // 3. Queue 를 지정합니다. channel.queue_declare(queue='hello') // 4. publish channel.basic_publish(exchange='', routing_key='hello', body='Hello World!')consume.py
import pika def callback(ch, method, properties, body): print(" [x] Received %r" % body) if __name__ == "__main__": credentials = pika.PlainCredentials('username', 'password') parameters = pika.ConnectionParameters( 'localhost', credentials=credentials, heartbeat=5) connection = pika.BlockingConnection(parameters) channel = connection.channel() channel.basic_consume(queue='hello', auto_ack=True, on_message_callback=callback) channel.start_consuming()아래 이미지는 consumer 의 connection 와 channel 입니다.

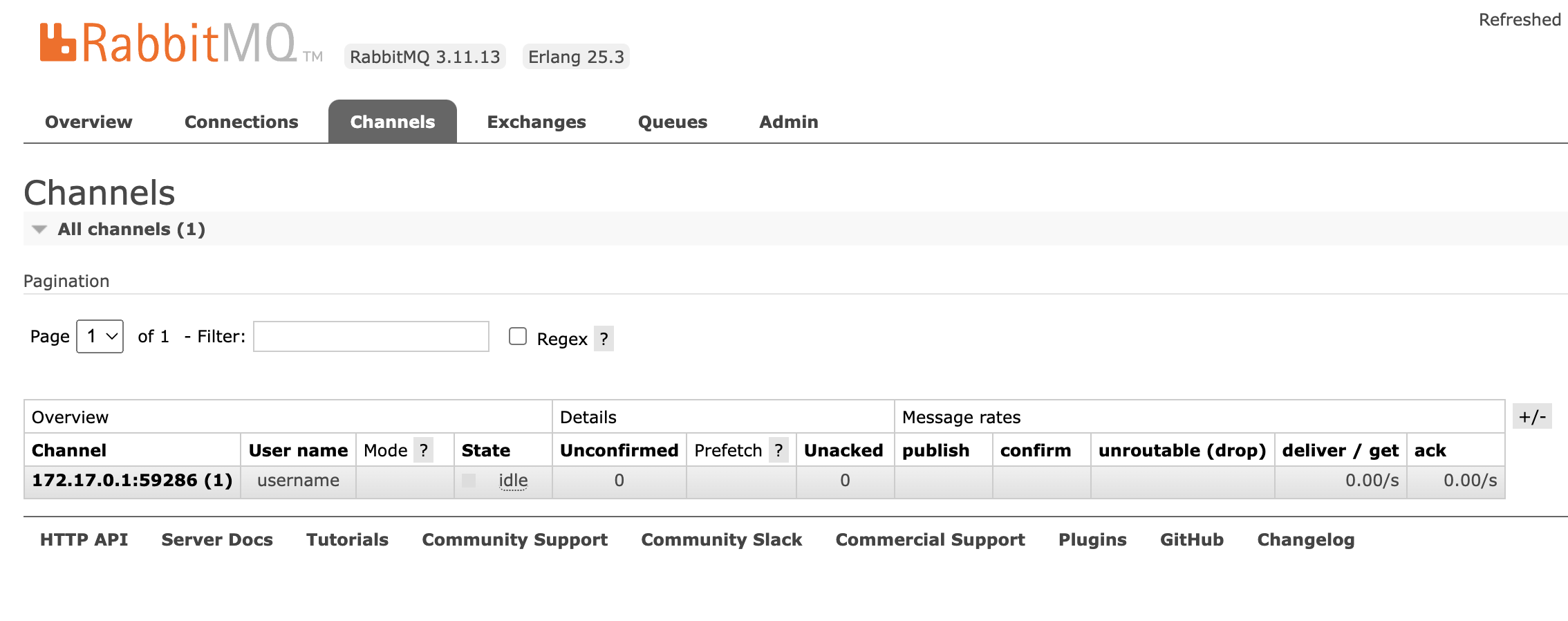
각각 1개의 connection 과 channel 이 생성됩니다.
아래 이미지들은 producer 의 connection 과 channel 이 추가된 이미지입니다.


 반응형
반응형'BigData' 카테고리의 다른 글
Avro Serialization 알아보기. (0) 2023.10.05 Avro File 알아보기 (0) 2023.10.04 apache spark 란 (0) 2023.01.12 hdfs (hadoop) 에 대해서 (0) 2023.01.11 RocksDB 알아보기 (0) 2021.12.15