-
[Spark] SortMergeJoin 알아보기Spark 2024. 8. 17. 08:24반응형
- 목차
- SortMergeJoin 이란 ?
- Reduce Stage 의 ShuffledRowRDD.
- Reduce Stage 의 MapPartitionsRDD.
- k-ways merge.
- SortMergeJoinExec.
SortMergeJoin 이란 ?
SortMergeJoin 은 SparkSQL 의 여러가지 Join 방식 중의 하나입니다.
가장 대표적인 Join 방식의 하나로써 이름처럼 Sort 과 Merge 가 주된 알고리즘으로 사용됩니다.
우선 간단한 예시와 실행 계획 그리고 DAG Visualization 을 확인해보겠습니다.
import spark.implicits._ import org.apache.spark.sql.types._ spark.conf.set("spark.sql.autoBroadcastJoinThreshold", -1) case class User(id: Int, name: String) case class Flag(name: String, bool: Boolean) val df1 = Seq(User(1, "a"), User(2, "b")).toDF() val df2 = Seq(Flag("a", true), Flag("b", false)).toDF() val joined = df1.join(df2, Seq("name")) joined.queryExecution.executedPlan // joined.queryExecution.debug.codegen()AdaptiveSparkPlan isFinalPlan=false +- Project [name#24, id#23, bool#33] +- SortMergeJoin [name#24], [name#32], Inner :- Sort [name#24 ASC NULLS FIRST], false, 0 : +- Exchange hashpartitioning(name#24, 200), ENSURE_REQUIREMENTS, [plan_id=36] : +- LocalTableScan [id#23, name#24] +- Sort [name#32 ASC NULLS FIRST], false, 0 +- Exchange hashpartitioning(name#32, 200), ENSURE_REQUIREMENTS, [plan_id=37] +- LocalTableScan [name#32, bool#33]
실행 계획을 살펴보면 위와 같이 Relation -> Exchange -> Sort -> Join 의 순서로 이어집니다.
Exchange 는 Hash Partitioning 을 사용하며, Join Key 를 기준으로 파티셔닝을 하게 됩니다.
그리고 이를 경계로 새로운 Reduce Stage 가 생성됩니다.
이 Reduce Stage 에서 ShuffledRowDD -> MapPartitionsRDD -> ZippedPartitionsRDD 등으로 Task 가 연산을 처리합니다.
여기서 각 부분에 대해서 자세히 알아보겠습니다.
Reduce Stage 의 ShuffledRowRDD.
ShuffledRowRDD 는 단순히 Map Task 에서 Join Key 를 기준으로 파티셔닝한 Shuffled Block 들을 가져오는 역할을 합니다.
일종의 ShuffleReader, BlockStoreShuffleReader 로 표현되는 클래스들의 기능을 통해서 Shuffled Block 을 네트워크적으로 가져오게 되며,
이를 InternalRow 형식으로 변형하여 다음 단계로 넘기게 됩니다.
이 과정에서 다음 단계는 Sort 연산에 해당합니다.
Reduce Stage 의 MapPartitionsRDD.
MapPartitionsRDD 로 이름이 표현되긴 했지만, 이 부분에서 실질적인 정렬이 수행됩니다.
SortExec.scala 의 doExecute 함수를 살펴보면 아래와 같이 MapPartitionsRDD 를 반환하게 됩니다.
protected override def doExecute(): RDD[InternalRow] = { val peakMemory = longMetric("peakMemory") val spillSize = longMetric("spillSize") val sortTime = longMetric("sortTime") child.execute().mapPartitionsInternal { iter => val sorter = createSorter() val metrics = TaskContext.get().taskMetrics() // Remember spill data size of this task before execute this operator so that we can // figure out how many bytes we spilled for this operator. val spillSizeBefore = metrics.memoryBytesSpilled val sortedIterator = sorter.sort(iter.asInstanceOf[Iterator[UnsafeRow]]) sortTime += NANOSECONDS.toMillis(sorter.getSortTimeNanos) peakMemory += sorter.getPeakMemoryUsage spillSize += metrics.memoryBytesSpilled - spillSizeBefore metrics.incPeakExecutionMemory(sorter.getPeakMemoryUsage) sortedIterator } }그리고 이 과정에서 실질적인 정렬이 적용됩니다.
UnsafeExternalRowSorter 라는 클래스를 통해서 안정적인 정렬 연산이 수행되구요.
그 내부적으로 Disk Spill, File 기반의 Sort, k-ways merge 등의 기능이 수행됩니다.
이렇게 정렬을 마친 후에 정렬된 데이터들은 다음 Node 로 이동합니다.
다음 Node 는 SortMergeJoinExec 으로부터 생성된 ZippedPartitionsRDD 와 MapPartitionsRDD 에 해당합니다.
k-ways merge.
k-way merge는 여러 개의 정렬된 데이터를 하나로 합치는 정렬 방식입니다.
예를 들어, 정렬된 여러 개의 작은 파일이 있다고 가정해 봅시다.
각 파일에서 하나씩 데이터를 꺼내고, 이 중 가장 작은 값을 선택해 최종 결과 배열에 추가합니다.
그 다음, 값을 꺼냈던 파일에서 다음 데이터를 가져와 다시 비교하는 과정을 반복합니다.이 방식은 정렬된 다수의 데이터 소스를 효율적으로 병합할 수 있어,
외부 정렬(external sort) 이나 병렬 정렬 결과를 합칠 때 자주 사용됩니다.특히, MySQL 과 같은 데이터베이스에서 정렬 시에 File Sorting 이라는 이름으로 사용되곤합니다.
SortMergeJoinExec.
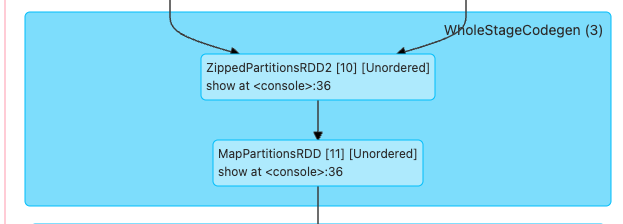
SortMergeJoinExec는 정렬된 두 입력 RDD를 받아, 내부에서 ZippedPartitionsRDD 와 MapPartitionsRDD 를 통해 Join 연산을 수행합니다.
ZippedPartitionsRDD 는 N 개의 RDD 를 입력으로 받아서 이를 List(rdd1, rdd2) 형식으로 변환합니다.
ZippedPartitionsBaseRDD[V](sc, List(rdd1, rdd2), preservesPartitioning)그리고 이러한 데이터들이 MapPartitionsRDD 로 넘어가게 됩니다.
MapPartitionsRDD 는 RDD1 과 RDD2 의 Partition 데이터들을 Iterable[InternalRow] 형태로 전달받게 됩니다.
그리고 이들은 아래와 같은 이중 반복문을 순회하면서 동일한 Key 를 가지는 Row 들끼리 Join 연산을 적용합니다.
SortMergeJoinExec.scala 의 def doExecute 함수
while (rightMatchesIterator != null) { if (!rightMatchesIterator.hasNext) { if (smjScanner.findNextInnerJoinRows()) { currentRightMatches = smjScanner.getBufferedMatches currentLeftRow = smjScanner.getStreamedRow rightMatchesIterator = currentRightMatches.generateIterator() } else { currentRightMatches = null currentLeftRow = null rightMatchesIterator = null return false } } joinRow(currentLeftRow, rightMatchesIterator.next()) if (boundCondition(joinRow)) { numOutputRows += 1 return true } }결론적으로
- Joining Key 를 기준으로 Sorting 을 수행한다.
- ZippedPartitionRDD 에서 2개의 RDD 가 하나의 Tuple2 형태로 묶이게 된다.
- SortMergeJoinExec 의 MapPartitionsRDD 연산에서 이중 반복문을 통해 Join 이 수행된다.
https://westlife0615.tistory.com/42
[Spark] Broadcast Join 연산 알아보기 ( spark.sql.autoBroadcastJoinThreshold )
- 목차 들어가며.SparkSQL 에서 2개의 DataFrame 을 기준으로 Join 연산을 수행할 수 있습니다.이때에 BroadcastJoin, SortMergeJoin, ShuffledHashJoin 등의 Join 전략을 채택하여 실행 계획을 구성하며,특히 autoBroadca
westlife0615.tistory.com
반응형'Spark' 카테고리의 다른 글
[Spark] RDD cartesian 연산 알아보기 ( CrossJoin, Cartesian Product ) (0) 2024.08.23 [Spark] Pivot 내부 동작 원리 알아보기 (0) 2024.08.17 [Spark] DataFrameReader 와 Parquet 최적화 알아보기 (Column Pruning, Predicate Pushdown) (0) 2024.08.15 [Spark] explode 함수와 Generate 연산자 알아보기 (0) 2024.08.15 [Spark] DataFrameWriter PartitionBy 알아보기 (0) 2024.08.12
