-
[Kafka] Partition 알아보기Kafka 2024. 5. 12. 11:30728x90반응형
- 목차
키워드.
- Topic
- Partition
- Replication
들어가며.
이번 글에서는 Kafka Topic 의 Partition 에 대해서 상세히 알아보는 시간을 가지려고 합니다.
Partition 이 가지는 여러가지 중요 특징들에 대해서 최대한 많이 나열해보려고 합니다.
Topic 과 Partition.
Kafka 는 Topic 이라는 메시지 저장소가 존재합니다.
Kafka CLI 를 통해서 최초로 Topic 을 생성하게 되는데요.
Kafka Cluster 가 생성된 이후에 아래와 같은 형식의 CLI 명령어를 통해서 Topic 의 생성이 가능합니다.
kafka-topics.sh --bootstrap-server localhost:9092 \ --topic test_topic --create --partitions 3 --replication-factor 1위 명령어를 분석해보면 다음과 같습니다.
"kafka-topic.sh" 은 Kafka Topic 과 관련된 명령어를 제공합니다.
"--topic test_topic" 은 Topic 의 이름을 설정합니다.
이로써 "test_topic" 이라는 이름으로 카프카 토픽이 생성됩니다.
"--partition 3" 은 3개의 Partition 을 생성함을 의미합니다. 이번 글의 주제와 관련된 설정인데요.
Partition 은 Topic 의 Part 라는 의미를 가집니다.
즉, Topic 이라는 메시지의 저장소의 한 부분을 뜻합니다.
Partition 은 여러개로 설정할 수 있어서, 일반적으로 하나의 Topic 은 여러 Partition 들로 구성됩니다.
아래 이미지는 "Kafdrop" 이라는 Kafka UI 툴에서 확인할 수 있는 Partition Detail 정보입니다.
하나의 Topic 이 3개의 Partition 으로 구성된다면 아래와 같은 결과를 확인할 수 있습니다.

Partition 의 갯수가 많으면 무엇이 좋은가 ?
일반적으로 하나의 Topic 은 여러개의 Partition 들로 구성된다고 말씀드렸습니다.
그럼 하나의 Topic 이 하나의 Partition 보다 여러 Partition 들로 구성하는 것의 장점이 무엇일까요 ?
1. 데이터의 조회의 속도가 빨라집니다.
Kafka Consumer 는 Topic 의 메시지를 조회하는 서버입니다.
일반적으로 하나의 Kafka Consumer 는 하나의 Partition 의 메시지를 조회합니다.
즉 Partition 이 10개이면 Kafka Consumer 도 10개로 구성하여 효율적으로 메시지를 조회할 수 있습니다.
(여기서 효율적이란 말은 메시지를 빠르게 조회할 수 있습니다. )
N 개의 Partition 과 N 개의 Consumer 를 구성할 수 있습니다.
2. 데이터를 분산 저장할 수 있습니다.
Kafka Cluster 는 여러 브로커들로 구성됩니다.
하나의 Topic 이 생성될 때에 여러 Partition 들이 생성되는데, 이 Partition 들은 여러 브로커가 나뉘어 관리합니다.
이를 Partition 의 Leader Broker 라고 부르는데요.
아래 이미지를 보시면 0번 Partition 의 Leader Broker 는 2번, 1번 Partition 의 Leader Broker 는 3번,
2번 Partition 의 Leader Broker 는 1번으로 설정되어 있습니다.

이러한 방식으로 브로커가 특정 Partition 을 전담하는 구조를 취합니다.
즉 하나의 서버가 (브로커가) 하나의 Partition 을 안정적으로 저장/관리하는 구조를 취합니다.
정리하면 Topic 이 여러 Partition 들을 둠으로써 조회의 속도와 데이터 저장의 안정성을 향상시킬 수 있습니다.
Partition 과 Broker 의 관계.
하나의 Topic 은 여러 Partition 들로 구성됩니다.
그리고 생성된 Partition 들은 여러 Broker 로 나뉘어 관리됩니다.
1 ~ 9 까지인 총 9개의 Partition 이 존재하고, 3개의 브로커가 존재한다면
3개의 브로커는 랜덤하게 3개의 Partition 들을 나누어 관리합니다.
그리고 이 브로커는 Partition 의 Leader Broker 가 됩니다.
Leader Broker 는 메시지의 Write/Read 시에 이름과 같이 Leader 로써 동작합니다.
Producer 가 생성을 요청하는 메시지를 전달받아 저장하고, Consumer 가 요청하는 데이터를 제공합니다.
아래의 이미지처럼 2개의 Topic, 5개의 Partition 그리고 3개의 Broker 가 존재할 때에,
3개의 브로커는 아래와 같은 형식으로 5개의 Partition 들을 관리합니다.
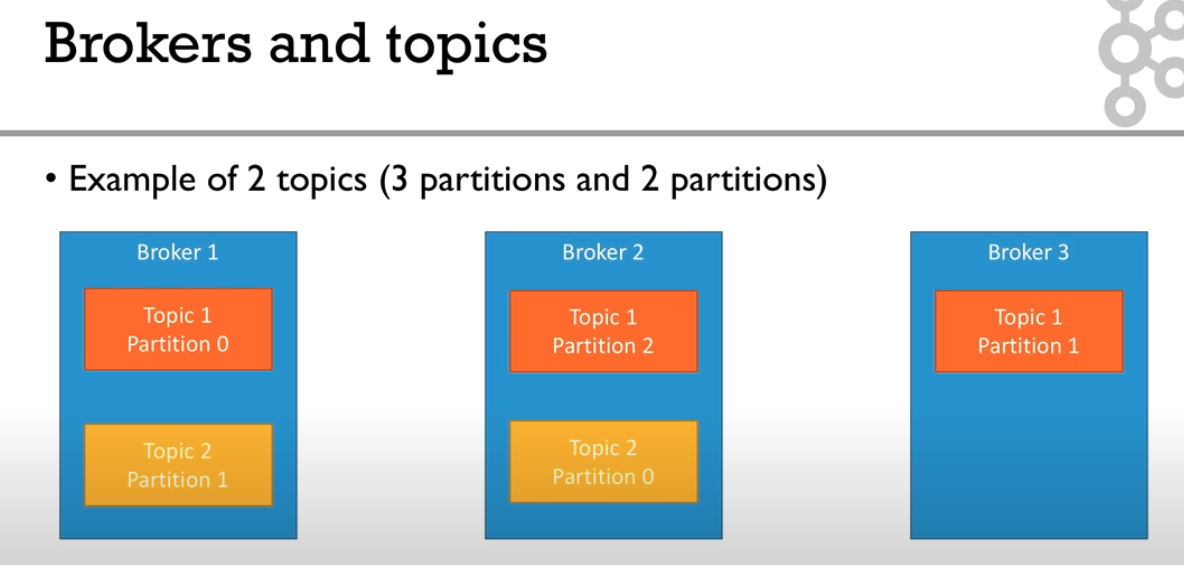
출처 : https://www.youtube.com/watch?v=ZOU7PJWZU9w&list=PLt1SIbA8guusxiHz9bveV-UHs_biWFegU&index=5 또 다른 예시로써 아래의 이미지가 있습니다.
3개의 Partition, 3개의 Replication Factor 을 가지는 Topic 과 3개의 브로커가 존재합니다.
아래 이미지에서 붉은색의 Partition 을 Leader Partition 을 의미합니다.
그리고 붉은색 Partition 을 가지는 Broker 가 Partition 의 Leader Broker 가 됩니다.
녹색의 Partition 은 Replication 역할을 수행합니다.

https://b-nova.com/en/home/content/why-you-should-know-apache-kafka/ Partition 의 개수가 Broker 의 개수보다 많은 경우.
Partition 의 개수가 Broker 의 개수보다 많은 경우에 하나의 Broker 는 여러개의 Partition 을 책임지게 됩니다.
실제 사례를 설명드리면, 아래의 이미지는 3개의 브로커와 6개의 Partition 을 가지는 "six_partitions_topic" 이라는 토픽의 상세 정보입니다.

0 부터 5 까지의 Partition 으로 구성되며, 브로커는 1,2,3 인 3개의 브로커가 존재합니다.
1번 브로커는 0, 4번 파티션의 Leader Broker,
2번 브로커는 2, 5번 파티션의 Leader Broker,
3번 브로커는 1, 3번 파티션의 Leader Broker 로 결정됩니다.
이러한 Partition 과 Broker 의 관계를 Partition Ownership 이라고 부릅니다.
Replication.
아래의 Kafka CLI 는 Topic 을 생성하는 명령어입니다.
여기서 주목할 옵션은 "--replication-factor 3" 에 해당하는 설정인데요.
이는 "test_topic" 이라는 이름의 토픽은 3개의 Partition 과 3개의 Replication 을 구축함을 의미합니다.
kafka-topics.sh --bootstrap-server localhost:9092 \ --topic test_topic --create --partitions 3 --replication-factor 3그럼 Replication 은 무엇일까요 ?
Replication 은 이름에서 유추할 수 있듯이 Partition 을 복제합니다.
Partition 와 Broker 의 관계에서 말씀드렸듯이, 하나의 Partition 은 이를 관리하는 Broker 가 존재합니다.
즉, 하나의 Partition 은 이를 주도적으로 관리하는 Leader Broker 가 존재합니다.
여기서 --replication-factor 가 2로 설정된다면, 이는 2개의 Replication 이 필요함을 뜻합니다.
그림으로 예시를 들어보겠습니다.
아래 예시는 1개의 Topic 이 존재하며, 이 Topic 은 3개의 Partition 을 가집니다.
그리고 3개의 브로커로 구성된 Kafka Cluster 입니다.
또한 --replication-factor 가 2로 설정되어 있습니다.
그래서 3개의 Broker 는 각각 1개의 Partition 을 관리하는 Leader Broker 가 되구요.
2개의 Replication 이 되어야하므로 각 Broker 는 1개의 복제된 Partition 을 가집니다.
요약하면,
- Broker 1 : Partition 0 과 복제된 Partition 1 을 관리함.
- Broker 2 : Partition 1 과 복제된 Partition 2 을 관리함.
- Broker 3 : Partition 2 과 복제된 Partition 0 을 관리함.
참고로 replication-factor 2 이 의미하는 바는 1개의 Primary Partiiton 과 1개의 Replication Partition
replication-factor 3 이 의미하는 바는 1개의 Primary Partiiton 과 2개의 Replication Partition 를 뜻합니다.

출처 : https://docs.confluent.io/kafka/design/replication.html 아래 이미지는 Replication 을 설명하기 위한 또다른 예시입니다.
아래 예시는 4개의 Broker 가 존재하고 하나의 Topic 은 4개의 Partition 들로 구성됩니다.
그리고 replication factor 는 3으로 설정되어 있습니다.
그래서 4개의 브로커는 각각 하나의 Partition 의 Leader Broker 로 설정되어있고,
replication factor 가 3이기에 여분의 Partition 을 복제하고 있습니다.
요약하면,
- Broker 1 : Partition 1 과 복제된 Partition 3, 복제된 Partition 4 을 관리함.
- Broker 2 : Partition 2 과 복제된 Partition 1, 복제된 Partition 4 을 관리함.
- Broker 3 : Partition 3 과 복제된 Partition 1, 복제된 Partition 2 을 관리함.
- Broker 3 : Partition 4 과 복제된 Partition 2, 복제된 Partition 3 을 관리함.

출처 : https://www.confluent.io/blog/hands-free-kafka-replication-a-lesson-in-operational-simplicity/ Topic 과 Partitioner ( Round-Robin, Sticky ... )
메시지는 Kafka Producer 에 의해서 생성됩니다.
Producer 는 특정 토픽을 지정하여 생성할 메시지를 브로커에게 전달하는데요.
일반적으로 Round-Robin 방식으로 저장되어 어떤 메시지가 어떤 Partition 에 저장되는지 랜덤하게 결정됩니다.
Kafka Record 의 key 가 None, Null 인 경우.
Kafka Record 는 key, value 로 구성됩니다.
아래의 이미지와 같이 timestamp, key, value, header 등으로 구성됩니다.
value 는 실질적으로 저장하고자하는 데이터가 저장되는 위치입니다.
그리고 여타 메타데이터들이 key 영역에 저장되는데요.
만약 key 에 값이 설정되어 있지 않으면, Kafka Record 는 저장될 Partition 이 Round-Robin 방식으로 결정됩니다.

https://developer.confluent.io/courses/architecture/broker/ Kafka Record 의 key 가 None, Null 이 아닌 경우.
key 가 비어있지 않다면, 이는 Hash Partitioner 로써 동작합니다.
즉, 동일한 Key 를 가지는 Kafka Record 는 동일한 Partition 으로 저장이 가능하죠.
카프카는 동일한 Key 를 가지는 Record 가 동일한 Partition 에 저장되는 것을 전적으로 보장합니다.
그래서 데이터의 성격이나 비즈니스 요구사항에 따라서 어떤 값을 Key 에 적용할지가 달라집니다.
예를 들어, 거래데이터가 존재하고 거래데이터는 Account ID 라는 계좌 식별값이 있다고 가정하겠습니다.
그리고 이러한 경우에 Account ID 를 Key 로 설정하여, 동일한 계좌에서 발생한 데이터는 동일한 Partition 으로 저장됨을 보장할 수 있습니다.
만약 글로벌 기업에서 수집하는 데이터라고 가정할때에 국가 정보가 Key 가 될 수도 있겠죠.
또한 적절한 Load Balancing 을 적용하여 모든 파티션에 균등한 데이터 저장을 원할 시에는 Key 를 생략할 수도 있습니다.
아래의 이미지와 같이 동일한 Key 를 가지는 Record 들은 동일한 Partition 으로 저장됨을 보장합니다.
 반응형
반응형'Kafka' 카테고리의 다른 글
[Kafka] BufferPool 알아보기 (org.apache.kafka:kafka-clients) (0) 2024.06.03 [Kafka] Timeindex 알아보기 (0) 2024.06.01 [Kafka] max.block.ms 알아보기 (0) 2024.02.18 [Kafka-Connect] Debezium MySQL Connector 구현하기 (0) 2024.02.18 [Kafka-Streams] Json 기반 Custom Serdes 구현하기 (0) 2024.02.17