-
[ClickHouse] primary.idx 파일 알아보기Database/Clickhouse 2024. 2. 28. 21:15반응형
- 목차
들어가며.
이번 글에서는 ClickHouse 의 primary.idx 파일에 대해서 알아보려고 합니다.
primary.idx 는 클릭하우스의 MergeTree Table 의 Primary Index 의 Entry 들을 관리하는 파일입니다.
MergeTree Table 은 반드시 PRIMARY KEY 또는 ORDER BY 선언을 통해서 Primary Index 를 지정해야합니다.
이렇게 Primary Index 가 지정된 이후에 해당 테이블에 데이터가 추가되면 primary.idx 파일에 Index Entry 들이 기록되게 됩니다.
이어지는 내용에서 Index Entry 는 어떤 구조를 취하며,
Parts, Granule, Sparse Index, Mark File 등에 대해서 자세히 알아보는 시간을 가지도록 하겠습니다.
granule 이란 ?
ClickHouse MergeTree Table 은 granule 단위로 데이터를 관리합니다.
granule 은 데이터를 관리하는 단위라고 생각할 수 있구요.
아래 이미지처럼 granule 단위로 여러 데이터들이 관리됩니다.

granule 의 크기 설정은 index_granularity 옵션을 통해서 설정할 수 있습니다.
아래의 Create Table DDL 과 같이 index_granularity 가 설정됩니다.
일반적으로 하나의 granule 이 관리하는 Row 의 갯수는 8192 가 주로 설정됩니다.
CREATE TABLE default.test ( `id` LowCardinality(String), `date` DATETIME ) ENGINE MergeTree() PARTITION BY toYYYYMM(date) ORDER BY tuple(date) SETTINGS index_granularity = 8192ClickHouse 는 Column Based 데이터베이스이다 보니 각 칼럼마다 granule 이 할당되구요.
각 칼럼의 데이터들이 Order By 의 순서에 따라서 granule 에 저장되는 구조이죠.
Parts 와 Granule 의 관계에 대해서.
좀 더 나아가서 Part 와 Granule 의 관계에 대해서 알아보겠습니다.
ClickHouse Parts 의 상세한 설정은 아래의 링크로 대체하겠습니다.
https://westlife0615.tistory.com/737
[ClickHouse] Parts & Partition 알아보기
- 목차 들어가며. 이번 글에서는 ClickHouse 의 MergeTree 엔진에서 사용되는 Parts 와 Partition 에 대해서 알아보려고 합니다. Partition 은 MergeTree Table 에 생성되는 데이터의 물리적인 단위입니다. Table 은 P
westlife0615.tistory.com
https://westlife0615.tistory.com/565
[ClickHouse] Block 알아보기
- 목차 들어가며. 이번 글에서는 ClickHouse 의 Block 의 개념에 대해서 알아보려고 합니다. ClickHouse MergeTree 엔진의 Table 을 생성하고, 해당 테이블에 데이터를 추가하게 되면 Parts 가 생성됩니다. ClickH
westlife0615.tistory.com
https://westlife0615.tistory.com/598
[ClickHouse] Compact Wide Parts 알아보기 ( part_type )
- 목차 들어가며. 이번 글에서는 ClickHouse MergeTree 의 part_type 에 대해서 알아보려고 합니다. 먼저 Parts 에 대한 자세한 설명은 아래 링크로 대신하도록 하겠습니다. https://westlife0615.tistory.com/737 [Click
westlife0615.tistory.com
클릭하우스의 MergeTree Table 은 Insert Query 에 의해서 Parts 파일이 생성됩니다.
그리고 이 Parts 파일들은 Merge Operation 의 대상이 됩니다.
즉, 여러개의 Part 들이 하나의 큰 Part 로 병합됩니다.
이 Parts 파일은 내부적으로 여러개의 granule 들로 관리됩니다.
Parts 는 물리적인 실제 파일이며, 그 Parts 파일 내부에서 여러 granule 들이 다루어 집니다.
그래서 granule 은 논리적 개념으로 볼 수 있죠.
index_granularity 로 설정된 Row 의 갯수를 단위로 여러개의 granule 들이 하나의 Parts 파일을 구성합니다.
좀 더 나아가서 Parts 파일은 실질적인 칼럼의 값들을 저장하는 bin 파일이 존재하고,
bin 파일 내부에 granule 들이 위치합니다.
아래 이미지를 보게되면,
Part 는 data.bin 파일을 가집니다.
그리고 data.bin 파일 내부는 여러 Granule 로 나뉘어지죠.
<출처 : https://jack-vanlightly.com/analyses/2024/1/23/serverless-clickhouse-cloud-asds-chapter-5-part-1>
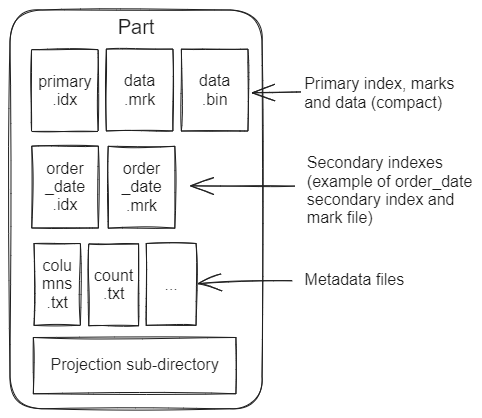

출처 : https://jack-vanlightly.com/analyses/2024/1/23/serverless-clickhouse-cloud-asds-chapter-5-part-1 Primary Index.
먼저 ClickHouse MergeTree Table 의 Primary Index 에 대해서 알아보겠습니다.
ClickHouse 의 Primary Index 는 일반적인 OLTP 데이터베이스의 Primary Index 와 성격이 다릅니다.
OLTP 의 예로써 MySQL 의 Primary Index 를 살펴보면 MySQL 의 Primary Index 는 모든 Row 를 Indexing 의 대상으로 삼습니다.
예를 들어, 아래와 같은 테이블이 존재한다고 가정하겠습니다.
create table oltp_table ( id int, data varchar, primary key (id) );이때에 "oltp_table" 테이블이 1만개의 Row 를 생성되었다고 할 때에 1만개의 Row 는 모두 Indexing 됩니다.
그래서 Row 의 갯수도 1만개 & Index Entry 의 갯수도 1만개가 됩니다.
이는 특정 데이터를 굉장히 빠른 속도로 조회할 수 있도록 돕습니다.
대신에 데이터 생성의 속도가 느려지는 Trade-Off 가 있죠.
반면 ClickHouse 의 Primary Index 는 동일한 이름을 사용하지만 그 성격이 다릅니다.
ClickHouse 는 데이터를 그룹단위로 관리하게 되며, 개별적인 데이터를 인덱싱하지 않습니다.
즉, 테이블 설정값으로 index_granularity 가 100 이라면 데이터들인 100 개 단위로 관리됩니다.
그래서 1만개의 데이터가 존재하면 100개의 granule 이 만들어지고 Primary Index 의 갯수 또한 100개가 됩니다.
아래 이미지처럼 MySQL 의 Primary Index 는 N:N 관계를 가지고,
ClickHouse 의 Primary Index 는 N : (N / index_granularity) 의 관계를 가집니다.
Index 와 Granule 이 1:1 관계가 되는 셈이죠.


Sparse Indexing.
위처럼 클릭하우스의 Primary Index 체계를 개별적인 Row 를 지칭하는 것이 아니라 Granule 을 지칭합니다.
그리고 실질적인 값인 Granule 내부의 특정 값을 지칭하는 Index 체계가 아닙니다.
그래서 이러한 인덱싱 방식을 느슨하다고하여 Sparse Indexing 이라고 부릅니다.
이는 Range Filtering, Range Indexing 에 특화되어 있습니다.
클릭하우스의 MergeTree Table 은 Order By 또는 Primary Key 에 의해서 반드시 정렬됩니다.
만약 Primary Key 로써 시각정보를 뜻하는`datetime` 이라는 칼럼이 적용되었다면 모든 데이터는 시간순서대로 정렬됩니다.
그리고 '2023-01-01' ~ '2024-01-01' 까지 1년치 데이터를 조회하게 된다면 이에 해당하는 모든 granule 들을 조회합니다.
1000개의 granule 들 중에서 2023년에 해당하는 granule 들이 메모리에 로드되고, 이 granule 들이 데이터 처리 대상이 됩니다.
이 때에 첫번째 granule 은 2022년도의 데이터를 일부 가질 수 있고, 마지막 granule 은 2024년도의 데이터를 일부 가질 수 있습니다.
이러한 비효율이 약간 존재하긴 하지만, Sparse Indexing 을 범위 데이터를 효율적으로 조회하기에 적합하며,
Insert Query 에 의한 데이터 생성 시에 Index Entry 의 생성 빈도가 적기 때문에 데이터 생성에서 좋은 효율을 보입니다.
primary.idx 파일이란 ?
이제 primary.idx 파일에 대해서 알아보도록 하겠습니다.
primary.idx 파일은 Primary Index Entry 를 저장하는 파일입니다.
계속 말씀드렸지만 클릭하우스의 Primary Index 는 Row 를 지칭하지 않고, Granule 을 지칭합니다.
그래서 primary.idx 파일 내부는 데이터의 값과 granule 의 위치를 가리킵니다.
예를 들어보겠습니다.
아래와 같은 테이블이 존재한다고 가정합니다.
CREATE TABLE default.test_index ( `id` LowCardinality(String), `date` DATETIME ) ENGINE MergeTree() PARTITION BY toYYYYMM(date) ORDER BY tuple(date)이 test_index 테이블의 primary.idx 는 아래와 같이 구성됩니다.
설명을 위해서 최대한 간략한 방식으로 표현하였습니다.
primary.idx 를 구성하는 값들인 index, mark 그리고 Primary Index 로 설정된 Column 들입니다.
저의 경우에는 datetime 이 Primary Index 로 사용되었기 때문에 datetime 칼럼이 primary.idx 파일에 작성됩니다.
+-----+-----+----------+ |index|mark |datetime | +-----+-----+----------+ |1 |1 |2023-01-01| // 1번 Granule 의 첫번째 datetime 값은 2023-01-01 +-----+-----+----------+ |2 |2 |2023-02-01| // 2번 Granule 의 첫번째 datetime 값은 2023-02-01 +-----+-----+----------+ |3 |3 |2023-03-01| +-----+-----+----------+ |4 |4 |2023-04-01| +-----+-----+----------+ |5 |5 |2023-05-01| +-----+-----+----------+index.
Primary Index Entry 의 index 값은 특정 granule 을 지칭하는 Number 에 해당합니다.
즉, 1번 index 는 1번 granule 을 지칭하는 인덱스의 넘버링입니다.
mark.
mark 는 mark 파일의 Entry 를 지칭합니다.
mark 는 bin 파일 내부의 granule 의 시작 위치 정보를 저장합니다.
그래서 "1번 granule 은 bin 파일 내부에서 몇번째 offset 에 위치한다." 와 같은 정보를 가집니다.
그래서 index 는 mark 를 지칭하며, mark 가 실제 데이터의 위치 정보를 가집니다.
첫번째 Primary Index Column 의 값.
datetime 은 granule 의 첫번째 데이터의 값이 사용됩니다.
그래서 primary.idx 의 Entry 는 mark 의 위치와 granule 의 첫번째 칼럼의 값이 사용됩니다.

출처 : https://jack-vanlightly.com/analyses/2024/1/23/serverless-clickhouse-cloud-asds-chapter-5-part-1 Mark File 이란 ?
Mark File 에 대해서 알아보겠습니다.
Mark File 은 Primary Index 와 함께 사용되어 인덱싱을 위한 구성요소입니다.
이 또한 물리적인 하나의 파일이구요.
bin 파일 내부에서 모든 Granule 의 물리적인 위치 정보를 가집니다.
Mark File 의 Entry 는 1번 Granule 의 시작 위치는 Offset 40 bytes, 10번 Granule 의 시작 위치는 Offset 400 bytes 와 같은 포맷으로 표현됩니다.
아래와 같은 형식으로 표현되며, Primary Index 가 지칭하는 Granule 의 위치로 빠르게 접근할 수 있죠.
+-------+--------+ |granule|offset | +-------+--------+ |1 |10 bytes| +-------+--------+ |2 |20 bytes| +-------+--------+ |3 |30 bytes| +-------+--------+ |4 |40 bytes| +-------+--------+ |5 |50 bytes| +-------+--------+ |6 |60 bytes| +-------+--------+Mark File 은 아래와 같이 mrk2 확장자를 가지는 파일입니다.
각 칼럼마다 mrk2 파일을 가지구요.
아래 예시에서는 date 와 id 칼럼이 사용되는 테이블이라서 2개의 mrk2 파일을 가집니다.
checksums.txt columns.txt count.txt date.bin date.mrk2 default_compression_codec.txt id.bin id.mrk2 minmax_date.idx partition.dat primary.idx이는 Parts 의 pary_type 이 Compact Type 과 Wide Type 에 대해서 다른 파일명을 가지는데요.
Compact Type 인 경우에는 data.mrk3 의 파일명과 확장자를 가집니다.
Compact Type 에서는 모든 칼럼이 하나의 파일로써 관리되기 때문에 data.mrk3 으로 파일명이 고정됩니다.
이후에 여러 차례 Merge Operation 이 적용된 이후에 Wide Type 으로 변경이 되면
mrk2 라는 확장자를 가지게 되고, 모든 칼럼 별로 Mark FIle 이 생성됩니다.
반응형'Database > Clickhouse' 카테고리의 다른 글
[ClickHouse] Parts & Partition 알아보기 (0) 2024.02.29 [ClickHouse] ReplicatedMergeTree 테이블 Backup 적용하기 (0) 2024.02.29 [ClickHouse Config] listen_host 설정 알아보기 (0) 2024.02.28 [Clickhouse] ReplicatedMergeTree 알아보기 (0) 2024.02.18 [Clickhouse] Docker 로 Clickhouse 구현하기 (2) 2024.02.17
