-
[Flink] JSON FileSink 만들어보기 (Row Format)Flink 2024. 2. 12. 10:12728x90반응형
- 목차
들어가며.
이번 글에서는 Flink DataStream Connector 중에서 File Sink 에 대해서 다루어보려고 합니다.
특히 JSON File 을 취급하는 File Sink 에 대해서 작성할 예정이구요.
관련된 구성요소들과 특징들에 대해서 작성해보겠습니다.
Row-encoded Format.
JSON 파일의 특징은 텍스트 기반의 파일이면서 Row 단위로 데이터를 저장합니다.
이는 csv 파일과 동일한 특징을 가집니다.
FileSink Connector 는 인코딩을 수행하기 위해서 Row 또는 Bulk 기반의 포맷이 존재하며,
JSON 파일은 Row 기반의 인코딩 포맷을 사용합니다.
Stream Data 를 처리하는 Row Format FileSink 는 다음과 같이 구성됩니다.
0 부터 1만까지의 숫자를 출력 파일에 작성하는 FileSink 프로그램입니다.
public static void main (String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime); env.setRuntimeMode(RuntimeExecutionMode.STREAMING); env.setParallelism(1); DataStream<String> source = env.fromSequence(0, 10000) .map(i -> "" + i); final String outputPath = "/tmp/output"; final FileSink<String> sink = FileSink .forRowFormat(new Path(outputPath), new SimpleStringEncoder<String>("UTF-8")) .withRollingPolicy(DefaultRollingPolicy.builder().build()) .withBucketAssigner(new BasePathBucketAssigner()) .build(); source.sinkTo(sink); env.execute(); }위 프로그램의 결과로써 아래와 같은 구조로 파일이 생성되구요.
/tmp/output 디렉토리 하위에 생성된 파일이 위치합니다.
그리고 파일의 내용은 0부터 1만까지의 숫자가 출력됩니다.
├── output │ └── part-54441ce9-e98e-452f-a11a-40decca7549a-00 1 2 3 4 5 6 7 8 // ... 생략 9998 9999 10000Json Encoder 구현하기.
이제 Pojo 데이터를 Json 형식으로 File Sink 를 수행하기 위한 Json Encoder 를 구현해보겠습니다.
Pojo 를 Json String 으로 Encoding 하기 위해서 Jackson 모듈을 사용하였습니다.
public static class JSONEncoder<IN> implements Encoder<IN> { private ObjectMapper objectMapper; public JSONEncoder () { this.objectMapper = new ObjectMapper(); } @Override public void encode(IN element, OutputStream stream) throws IOException { JsonNode json = objectMapper.convertValue(element, JsonNode.class); stream.write(json.toString().getBytes(Charset.forName("UTF-8"))); stream.write('\n'); } }실행 코드는 아래와 같습니다.
1만개의 Event Pojo 를 생성하고, 이를 Json 으로 직렬화하여 파일로 저장합니다.
public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime); env.setRuntimeMode(RuntimeExecutionMode.STREAMING); env.setParallelism(1); DataStream<Event> source = env.fromSequence(0, 10000) .map(i -> new Event( Instant.parse("2023-01-01T00:00:00.000Z").plus(i, ChronoUnit.HOURS).toEpochMilli(), "" + i) ); final String outputPath = "/tmp/output"; final FileSink<Event> sink = FileSink .forRowFormat(new Path(outputPath), new JSONEncoder<Event>()) .withRollingPolicy(DefaultRollingPolicy.builder().build()) .withBucketAssigner(new BasePathBucketAssigner()) .build(); source.sinkTo(sink); env.execute(); } public static class Event { public Long timestamp; public String data; public Event(Long timestamp, String data) { this.timestamp = timestamp; this.data = data; } } }< 파일 내용 >
// ...생략 {"timestamp":1704758400000,"data":"8952"} {"timestamp":1704762000000,"data":"8953"} {"timestamp":1704765600000,"data":"8954"} {"timestamp":1704769200000,"data":"8955"} {"timestamp":1704772800000,"data":"8956"} {"timestamp":1704776400000,"data":"8957"} {"timestamp":1704780000000,"data":"8958"} {"timestamp":1704783600000,"data":"8959"} {"timestamp":1704787200000,"data":"8960"} {"timestamp":1704790800000,"data":"8961"} // ...생략BucketAssigner.
FileSink Connector 는 BucketAssigner 기능이 존재합니다.
Bucket Assigner 는 생성된 파일들을 파일 구조로 저장할지를 결정합니다.
기본적으로 제공되는 BucketAssigner 는 두가지이며,
BasePathBucketAssigner 와 DateTimeBucketAssigner 입니다.
BasePathBucketAssigner.
BasePathBucketAssigner 는 Output Path 로 설정한 디렉토리 위치에 파일들을 저장합니다.
추가적인 계층 구조는 존재하지 않습니다.
만약 Output Path 가 "/tmp/output" 으로 설정되었다면, 생성되는 파일들은 아래 예시와 같이 output 디렉토리 하위에 위치하게 됩니다.
├── output │ ├── part-02e49d54-e7ee-431c-ba31-be38f3d65173-0 │ ├── part-040ee39a-0f87-4445-b5aa-4fce9c88af30-0 │ ├── part-04558ecf-79b9-4625-8b93-7f8f9b74f192-0 │ ├── part-04c7b0d4-6970-445f-9653-1f0cf95d8d26-0 │ ├── part-066f5615-a6a3-4762-8c6a-e12a84a7c7fd-0 │ ├── part-097ea513-8a4b-4001-a047-792a75053348-0 │ ├── part-0f881593-7bfc-4c2a-b089-9289e5ded16b-0 │ ├── part-1799f67d-6575-46e2-8304-a035476f94df-0 │ ├── part-1e5374cb-de6f-462d-8735-f9991c6bba1d-0 │ ├── part-1f39fb32-cb2f-4c94-8da3-cdeec509b94a-0 │ ├── part-1f56d2d4-0405-49f9-89bb-9c17e2e4d302-0 │ ├── part-235c8c3e-b441-4b2e-a488-65e802eb5d9a-0 │ ├── part-25cb31bc-1b0d-474b-8bd4-eb52caaa54da-0 │ ├── part-27ce3ea0-fbed-4c86-87e6-aad95ec020ae-0 │ ├── part-2861117c-e4f3-4e34-a49c-c0acb25d566d-0 │ ├── part-28ba46aa-d11a-4624-b1b5-d324cb604ba6-0DateTimeBucketAssigner.
Flink 는 Event Stream 을 처리하는 프레임워크이기 때문에 DateTime 과 관련하여 파일 위치를 설정하는 것이 유용합니다.
DateTimeBucketAssigner 는 시간을 기준으로 Bucketing 을 수행하기 때문에 시간단위로 File 의 계층 구조를 구성할 수 있습니다.
아래의 FileSink 는 DateTimeBucketAssigner 를 활용한 예시이구요.
저는 분단위로 Bucket Assignment 를 적용하였습니다.
final FileSink<Event> sink = FileSink .forRowFormat(new Path(outputPath), new JSONEncoder<Event>()) .withRollingPolicy(DefaultRollingPolicy.builder().build()) .withBucketAssigner(new DateTimeBucketAssigner<>("yyyy-MM-dd-HH-mm")) .build();결과는 아래 파일 계층구조처럼 분단위로 디렉토리가 설정됩니다.
하지만 이는 현재 시간을 반영하기 때문에 Event Time Semantics 로 설정하는 방법이 아닙니다.
├── output │ ├── 2024-02-11-16-22 │ │ ├── part-6047b1db-6360-47ae-9e7d-8a76edff8116-0 │ │ ├── part-6047b1db-6360-47ae-9e7d-8a76edff8116-1 │ │ └── part-6047b1db-6360-47ae-9e7d-8a76edff8116-2 │ └── 2024-02-11-16-23 │ └── part-27248823-7e91-430e-a73f-6d87587c4b31-0Custom Bucket Assigner 구현하기.
Event Time 을 기준으로 Bucketing 을 수행하는 방법에 대해서 설명하도록 하겠습니다.
아래 코드 예시는 Event Time 을 기준으로 파일 계층구조를 구성하는 FileSink 코드입니다.
public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime); env.setRuntimeMode(RuntimeExecutionMode.STREAMING); env.setParallelism(1); DataStream<Event> source = env.fromSequence(0, 72) .map(i -> new Event( Instant.parse("2023-01-01T00:00:00.000Z").plus(i, ChronoUnit.HOURS).toEpochMilli(), "" + i) ).assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ofHours(0)) .withTimestampAssigner((event, timestamp) -> event.timestamp)); final String outputPath = "/tmp/output"; final FileSink<Event> sink = FileSink .forRowFormat(new Path(outputPath), new JSONEncoder<Event>()) .withRollingPolicy(DefaultRollingPolicy.builder().build()) .withBucketAssigner(new BucketAssigner<>() { @Override public String getBucketId(Event element, Context context) { return LocalDateTime.ofInstant(Instant.ofEpochMilli(element.timestamp), ZoneOffset.UTC) .truncatedTo(ChronoUnit.HOURS) .format(DateTimeFormatter.ofPattern("yyyy-MM-dd-HH")); } @Override public SimpleVersionedSerializer<String> getSerializer() { return SimpleVersionedStringSerializer.INSTANCE; } }) .build(); source.sinkTo(sink); env.execute(); } public static class Event { public Long timestamp; public String data; public Event(Long timestamp, String data) { this.timestamp = timestamp; this.data = data; } } public static class JSONEncoder<IN> implements Encoder<IN> { private ObjectMapper objectMapper; public JSONEncoder () { this.objectMapper = new ObjectMapper(); } @Override public void encode(IN element, OutputStream stream) throws IOException { JsonNode json = objectMapper.convertValue(element, JsonNode.class); stream.write(json.toString().getBytes(Charset.forName("UTF-8"))); stream.write('\n'); } }├── output │ ├── 2023-01-01-00 │ │ └── part-c0e22d43-7641-41aa-93ac-f861034a1354-0 │ ├── 2023-01-01-01 │ │ └── part-2f92a2f2-49c6-41b3-95a4-3287d2b00223-0 │ ├── 2023-01-01-02 │ │ └── part-53592c1d-2ac6-443b-ad91-5ac5fd26a242-0 │ ├── 2023-01-01-03 │ │ └── part-8b99dbf7-f96c-446b-a132-e2854025363a-0 │ ├── 2023-01-01-04 │ │ └── part-23db3827-b655-469a-9e7b-a231114a61db-0 // ... 생략 │ ├── 2023-01-03-22 │ │ └── part-e8c2f1ca-57fa-47e7-bc7c-14e9b1067a20-0 │ ├── 2023-01-03-23 │ │ └── part-e3c3b49f-679c-43d4-83db-ce3ffadcacaf-0 │ └── 2023-01-04-00 │ └── part-0b4fcc61-0cc3-4ab6-b629-7a7f9c6e1bb3-0FileSink 에 BucketAssigner 익명클래스를 통해서 구현합니다.
getBucketId 함수의 내용은 Bucket 의 ID 를 생성하는 코드로 구성되는데요.
저의 경우에는 Event 의 Timestamp 를 시간단위로 Truncated 하여 BucketID 로 사용하였습니다.
final FileSink<Event> sink = FileSink .forRowFormat(new Path(outputPath), new JSONEncoder<Event>()) .withRollingPolicy(DefaultRollingPolicy.builder().build()) .withBucketAssigner(new BucketAssigner<>() { @Override public String getBucketId(Event element, Context context) { return LocalDateTime.ofInstant(Instant.ofEpochMilli(element.timestamp), ZoneOffset.UTC) .truncatedTo(ChronoUnit.HOURS) .format(DateTimeFormatter.ofPattern("yyyy-MM-dd-HH")); } @Override public SimpleVersionedSerializer<String> getSerializer() { return SimpleVersionedStringSerializer.INSTANCE; } }) .build();RollingPolicy.
이벤트 스트림 처리 분야에서 Rolling 이라는 표현이 자주 사용됩니다.
이벤트 스트림이란 끝없는 데이터의 흐름이며, 이를 Unbounded 라고 표현합니다.
Rolling 이라는 표현은 Unbounded Data Stream 을 Flush 할때에 사용되는 표현이고,
Kafka, Flink Stream 등의 영역에서 사용됩니다.
즉, 끝없는 이벤트 스트림에서 일부분의 데이터를 Write, Sink 하는 행위라고 생각하시면 됩니다.
그래서 Rolling Policy 는 "이벤트 스트림의 데이터를 언제 DataSink 에 저장할래 ? " 의 설정입니다.
Flink File Sink Connector 에서의 Rolling Policy 는 생성 중인 임시파일을 설정된 원격저장소에 영구적으로 저장하는 설정입니다.
Flink 의 File 들은 In-Progress --> Finished 로의 상태 변화가 존재하는데,
In-progress Files 들이 Rolling 되면서 원격 저장소로 영구적으로 옮겨집니다.
RollingPolicy 는 두가지가 존재합니다.
DefaultRollingPolicy 와 OnCheckpointRollingPolicy 입니다.
DefaultRollingPolicy.
DefaultRollingPolicy 는 용량 기준 그리고 시간 기준으로 FIle 을 생성합니다.
용량 기준은 생성 중인 파일이 몇 바이트 이상이 되면 생성 중인 파일을 닫고 새로운 파일을 생성합니다.
시간 기준도 유사합니다.
정해진 기준의 시간동안 하나의 파일을 생성하고, 기준 시간이 지나면 새로운 파일을 생성합니다.
DefaultRollingPolicy 는 용량과 시간 기준을 활용하여 File 의 갯수를 결정합니다.
참고로 DefaultRollingPolicy 에서 의미하는 시간 기준은 Event Time Semantics 를 따르지 않습니다.
시스템 시간을 따르니 이 점을 참고하셔야합니다.
withMaxPartSize.
먼저 용량 기준으로 어떻게 파일이 생성되는지에 대해서 알아보겠습니다.
용량 기준을 설정하는 방법은 withMaxPartSize 함수를 사용하는 것입니다.
코드 예시는 아래와 같습니다.
1024 즉 1KB 기준으로 파일을 생성합니다.
final FileSink<Event> sink = FileSink .forRowFormat(new Path(outputPath), new JSONEncoder<Event>()) .withRollingPolicy(DefaultRollingPolicy.builder() .withInactivityInterval(Duration.ofMinutes(1000)) .withRolloverInterval(Duration.ofMinutes(1000)) .withMaxPartSize(MemorySize.parse("1024")) .build()) .withBucketAssigner(new BasePathBucketAssigner()) .build();먼저 990 byte 의 데이터를 처리한 결과, 아래와 같이 1개의 파일이 생성됩니다.
990 part-1ca580bf-110f-42d6-8cc6-efe1ceeca9dc-0이번엔 3000 byte 정보의 데이터를 처리하였고, 아래와 같이 3개의 파일이 생성됩니다.
첫번째 파일은 1030, 두번째 파일은 1040 의 크기를 가집니다.
1030 part-0a781bce-671b-4b8f-b9c7-e3794601c5d2-0 1040 part-0a781bce-671b-4b8f-b9c7-e3794601c5d2-1 840 part-0a781bce-671b-4b8f-b9c7-e3794601c5d2-2withRolloverInterval.
시간 기준으로 Rolling Update 를 설정하기 위해서는 withRolloverInterval 함수를 사용합니다.
withRolloverInterval 는 파일을 생성하는 시간 기준입니다.
예시 코드는 아래와 같구요.
10초를 기준으로 파일이 생성됩니다.
( withMaxPartSize 는 넉넉히 1GB 로 설정하였습니다. )
final FileSink<Event> sink = FileSink .forRowFormat(new Path(outputPath), new JSONEncoder<Event>()) .withRollingPolicy(DefaultRollingPolicy.builder() .withInactivityInterval(Duration.ofSeconds(60)) .withRolloverInterval(Duration.ofSeconds(10)) .withMaxPartSize(MemorySize.parse("1073741824")) .build()) .withBucketAssigner(new BasePathBucketAssigner()) .build();< 생성된 파일 구조 >
424M part-ba6bf9d8-f617-4513-a46a-47c16f1ec5c3-0 12M part-ba6bf9d8-f617-4513-a46a-47c16f1ec5c3-1withInactivityInterval.
withInactivityInterval 은 Open 된 파일이 어떠한 Write 나 Append 동작없이 Idle 상태로 지속되는 허용 시간을 의미합니다.
즉, 파일이 생성되어 Open 되었는데 Inactivity 시간이 지속되면 파일을 닫아버립니다.
테스트를 위해서 아래와 같은 1분 주기로 데이터를 생성하는 DataSource 를 사용하였구요.
withInactivityInterval 는 30초로 설정하여 InactivityInterval 를 테스트하였습니다.
3개의 데이터들이 InactivityInterval 을 넘어서는 지연시간이 존재하므로 3개의 파일이 생성됩니다.
DataStream<Event> source = env.addSource(new SourceFunction<Event>() { @Override public void run(SourceContext<Event> ctx) throws Exception { Event event = new Event( Instant.parse("2023-01-01T00:00:00.000Z").toEpochMilli(), "1"); ctx.collect(event); Thread.sleep(1000 * 60); ctx.collect(event); Thread.sleep(1000 * 60); ctx.collect(event); Thread.sleep(1000 * 60); } @Override public void cancel() { } });final FileSink<Event> sink = FileSink .forRowFormat(new Path(outputPath), new JSONEncoder<Event>()) .withRollingPolicy(DefaultRollingPolicy.builder() .withInactivityInterval(Duration.ofSeconds(30)) .withRolloverInterval(Duration.ofSeconds(120)) .withMaxPartSize(MemorySize.parse("1073741824")) .build()) .withBucketAssigner(new BasePathBucketAssigner()) .build();< 생성된 파일 구조 >
39B 2 12 20:07 part-9ef84e4a-c1ba-470f-bb7f-f7346397f983-0 39B 2 12 20:08 part-9ef84e4a-c1ba-470f-bb7f-f7346397f983-1 39B 2 12 20:09 part-9ef84e4a-c1ba-470f-bb7f-f7346397f983-2OnCheckpointRollingPolicy.
OnCheckpointRollingPolicy 는 가장 일반적으로 사용되는 RollingUpdate 방식입니다.
Checkpoint 를 사용하기 때문에 내결함성이나 Exactly Once 를 구현할 수 있는 장점이 존재합니다.
아래 그림과 같이 Checkpoint 가 생성되면서 File 또한 Rolling Update 가 됩니다.
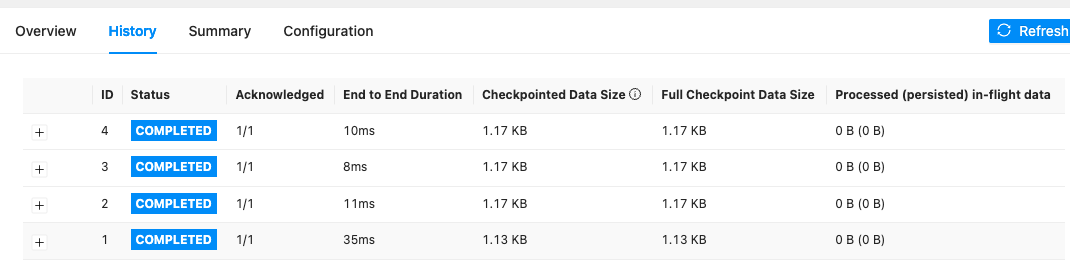
Checkpoint 와 OnCheckpointRollingPolicy 를 적용한 예시 코드는 아래와 같습니다.
public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration()); env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime); env.setRuntimeMode(RuntimeExecutionMode.STREAMING); env.setParallelism(1); env.enableCheckpointing(1000 * 10); env.getCheckpointConfig().setCheckpointStorage(new Path("file:///tmp/checkpoint")); DataStream<Event> source = env.fromSequence(0, 10000000) .map(i -> new Event( Instant.parse("2023-01-01T00:00:00.000Z").plus(i, ChronoUnit.HOURS).toEpochMilli(), "" + i) ).assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ofHours(0)) .withTimestampAssigner((event, timestamp) -> event.timestamp)); final String outputPath = "/tmp/output"; final FileSink<Event> sink = FileSink .forRowFormat(new Path(outputPath), new JSONEncoder<Event>()) .withRollingPolicy(OnCheckpointRollingPolicy.build()) .withBucketAssigner(new BasePathBucketAssigner()) .build(); source.sinkTo(sink); env.execute(); } public static class Event { public Long timestamp; public String data; public Event(Long timestamp, String data) { this.timestamp = timestamp; this.data = data; } } public static class JSONEncoder<IN> implements Encoder<IN> { private ObjectMapper objectMapper; public JSONEncoder () { this.objectMapper = new ObjectMapper(); } @Override public void encode(IN element, OutputStream stream) throws IOException { JsonNode json = objectMapper.convertValue(element, JsonNode.class); stream.write(json.toString().getBytes(Charset.forName("UTF-8"))); stream.write('\n'); } }< 생성된 파일 구조 >
47M part-ac41c832-1ec0-4488-91f5-14949acbe532-0 79M part-ac41c832-1ec0-4488-91f5-14949acbe532-1 80M part-ac41c832-1ec0-4488-91f5-14949acbe532-2 78M part-ac41c832-1ec0-4488-91f5-14949acbe532-3 80M part-ac41c832-1ec0-4488-91f5-14949acbe532-4 71M part-ac41c832-1ec0-4488-91f5-14949acbe532-5Output File Configuration.
생성되는 파일의 이름과 압축 방식 등을 설정할 수 있는 withOutputFileConfig 함수가 제공됩니다.
아래와 같은 형식으로 파일의 Prefix, Suffix 를 설정할 수 있습니다.
final String outputPath = "/tmp/output"; final FileSink<Event> sink = FileSink .forRowFormat(new Path(outputPath), new JSONEncoder<Event>()) .withRollingPolicy(DefaultRollingPolicy.builder().build()) .withBucketAssigner(new BasePathBucketAssigner()) .withOutputFileConfig(OutputFileConfig.builder() .withPartSuffix(".json") .withPartPrefix("test") .build()) .build();생성된 파일명은 아래와 같이 test Prefix 와 .json Suffix 가 추가됩니다.
test-3d5a3513-ebcb-4ef2-b1a7-a96f90c1222a-0.json마치며.
읽어주셔서 감사합니다.
혹시나 잘못된 내용일 있으면 피드백을 받아 수정하도록 하겠습니다.
반응형'Flink' 카테고리의 다른 글
[Flink] Async IO Retry Strategy 알아보기 (0) 2024.03.23 [Flink] Async IO 알아보기 ( AsyncDataStream ) (0) 2024.03.23 [Flink] Tumbling Time Window 알아보기 (TumblingEventTimeWindows) (0) 2024.02.12 [Flink] Window AllowedLateness 알아보기 (Watermark) (0) 2024.02.12 [Kryo] Kyro Serialization 알아보기 (0) 2024.02.05