-
[Spark] fold, reduce 알아보기 ( RDD, Action, Aggregation )Spark 2024. 1. 19. 23:10728x90반응형
- 목차
들어가며.
이번 글에서는 Spark 의 Action Operation 중의 하나인 fold 에 대해서 알아보려고 합니다.
fold 는 reduce, aggregate 와 함께 대표적으로 사용되는 Action 함수 중의 하나입니다.
fold 함수는 reduce 함수와 매우 유사한 점이 많습니다. 그만큼 직관적으로 이해하기도 편한 함수이죠.
하지만 Spark 는 Partition 이라는 개념과 더불어 fold 함수를 완벽하게 이해하기 어려운 부분이 존재하는데요.
이번 글에서 fold 함수에 대해서 자세히 알아보는 시간을 가지겠습니다.
Collection 자료구조에서의 reduce.
먼저 일반적인 프로그래밍 언어에서 제공되는 Collection 모듈에서 사용되는 reduce 에 대해서 알아보겠습니다.
제가 Collection 모듈이라고 이름을 붙인 개념은 단순히 List, Set, Tuple, Dict 등을 일컫는 자료구조를 의미합니다.
아래의 예시는 Python List 를 Sum 하는 reduce 예시입니다.
reduce 의 동작을 기본적으로 List 를 Item 으로, Vector 를 Scalar 로 표현하는데에 의의가 있습니다.
즉, 차원 축소에 의미가 있죠.
아래 프로그램의 결과는 1 부터 6 까지의 자연수를 더한 21 이 출력됩니다.
from functools import reduce list_data = [1, 2, 3, 4, 5, 6] result = reduce(lambda a, b: a + b, list_data) print(f'output: {result}') # output: 21이를 응용하여서 최대값, 최소값, 평균값 등의 연산 또한 가능합니다.
from functools import reduce list_data = [1, 2, 3, 4, 5, 6] result = reduce(lambda a, b: a if a > b else b, list_data) print(f'max output: {result}') result = reduce(lambda a, b: b if a > b else a, list_data) print(f'mean output: {result}') result = reduce(lambda a, b: a + b, list_data) print(f'avg output: {result / len(list_data)}')Spark 에서의 Reduce, Fold.
Spark 는 기본적으로 분산 처리 아키텍처를 취합니다.
따라서 동일한 Python List 를 연산하더라도, 정해진 Partition 의 갯수만큼 개별적으로 연산이 수행됩니다.
예를 들어보겠습니다.
아래의 예시에서는 glom 이라는 함수를 사용하여 RDD 가 어떠한 방식으로 Partition 을 생성하는지 살펴봅니다.
glom 함수는 Partition 으로 할당된 데이터들을 하나의 List 또는 Iterable 형태로 변형합니다.
Iterable 은 Flatten 하는 FlatMap 과 반대로 동작한다고 생각하시면 좋습니다.
아래의 결과를 보면 1개의 Partition 을 가지는 경우에는 [1,2,3,4,5,6] 과 같이 1개의 데이터가 취급됩니다.
반면 3개의 Partition 을 가지는 경우에는 [1, 2], [3, 4], [5, 6] 와 같이 3개의 데이터가 취급되며,
5개의 Partition 을 가질 때에는 [1], [2], [3], [4], [5,6] 와 같은 형식으로 데이터가 생성됩니다.
대략적인 glom 의 동작은 이해가 되시죠 ?
from pyspark import SparkConf, SparkContext conf = SparkConf().setAppName("test-parallelize") conf.setMaster('local[*]') conf.set("spark.driver.bindAddress", "localhost") sc = SparkContext(conf=conf) list_data = [1, 2, 3, 4, 5, 6] rdd = sc.parallelize(list_data, 1) output = rdd.glom().collect() print(f'output partition 1: {output}') # output partition 1: [[1, 2, 3, 4, 5, 6]] rdd = sc.parallelize(list_data, 3) output = rdd.glom().collect() print(f'output partition 3: {output}') # output partition 3: [[1, 2], [3, 4], [5, 6]] rdd = sc.parallelize(list_data, 5) output = rdd.glom().collect() print(f'output partition 5: {output}') # output partition 5: [[1], [2], [3], [4], [5, 6]] sc.stop()Spark Reduce 동작 확인해보기.
Spark RDD 의 Reduce 는 2가지 phase 로 동작합니다.
1. 각 Partition 에서의 Reduce , 2. Partition 의 결과를 Reduce 한 이후에 Driver Program 으로 전달.
첫번째 Reduce 는 Partition 별로 수행되는 Local Reducer , 두번째 Reduce 는 Partition 별 결과를 연산하는 Global Reducer 로 이해하시면 좋습니다.
from pyspark import SparkConf, SparkContext conf = SparkConf().setAppName("test-parallelize") conf.setMaster('local[*]') conf.set("spark.driver.bindAddress", "localhost") sc = SparkContext(conf=conf) list_data = [1, 2, 3, 4, 5, 6] rdd = sc.parallelize(list_data, 3) output = rdd.reduce(lambda a, b: a + b) print(f'output: {output}') # output: 21 sc.stop()이를 도식화해보면 아래와 같이 1, 2, 3, 4, 5, 6 의 리스트는 3개의 Partition 으로 구성될 수 있습니다.
그리고 reduce 를 통해서 각 Partition 의 값들은 연산의 결과를 출력합니다.
이는 Local Reducer 의 동작합니다.
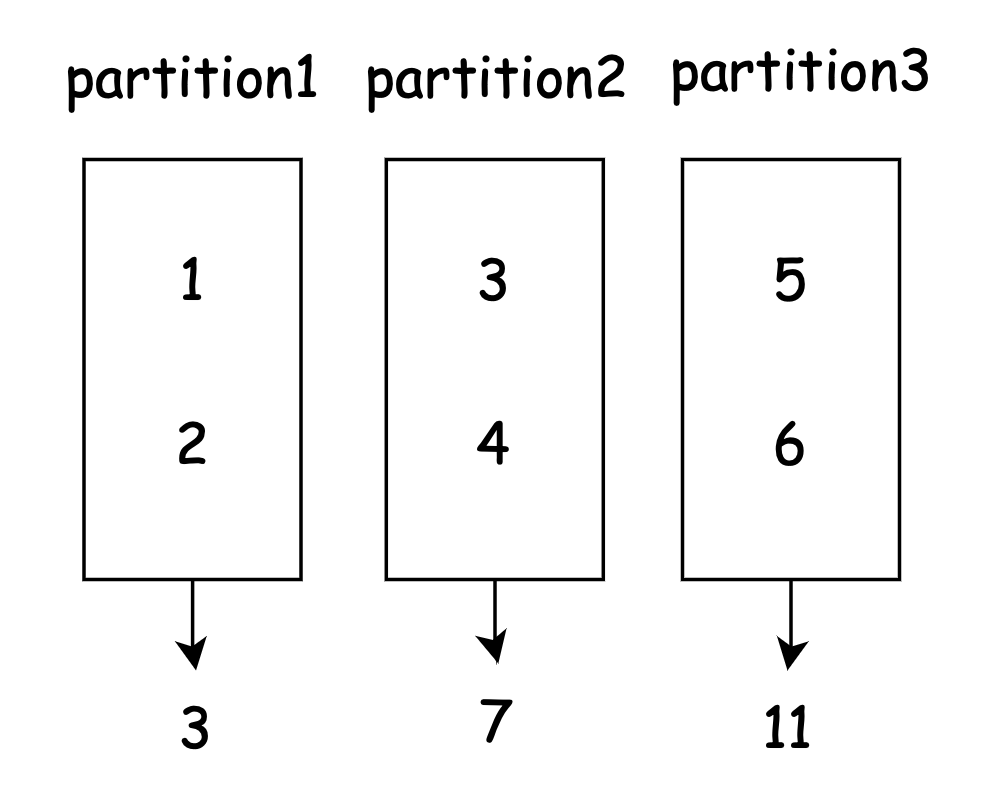
그리고 이렇게 생성된 각 Partition 의 출력인 3, 7, 11 는 다시 한번 Reducing 되어
3 + 7 + 11 = 21 이라는 최종적인 결과를 생산합니다.
Spark Fold 알아보기.
이제 Reduce 의 동작을 살펴보았기 때문에 Fold 의 동작을 알아보도록 하겠습니다.
Fold 는 Reduce 와 동일하되, 초기값이 존재한다는 점이 다릅니다.
예제 코드는 아래와 같으며, 초기값을 1 로 설정할 시에 결과는 25로 가 출력됩니다.
from pyspark import SparkConf, SparkContext conf = SparkConf().setAppName("test-parallelize") conf.setMaster('local[*]') conf.set("spark.driver.bindAddress", "localhost") sc = SparkContext(conf=conf) list_data = [1, 2, 3, 4, 5, 6] initial_value = 1 rdd = sc.parallelize(list_data, 3) output = rdd.fold(initial_value, lambda a, b: a + b) print(f'output: {output}') # output: 25 sc.stop()먼저 아래의 이미지와 같이 각 Partition 을 대상으로 Local Reducing 이 발생할 때에 Initial Value 1 이 연산됩니다.
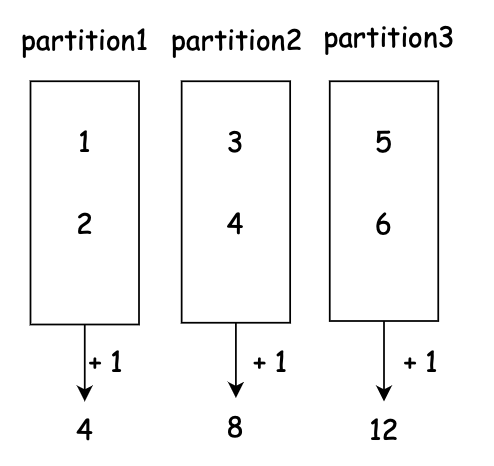
그리고 각 Partition 의 연산 결과인 4, 8, 12 를 연산할 때에서 Initial Value 1 이 연산에 관여합니다.
4 + 8 + 12 + 1 = 25
그래서 Initial Value 는 Local Reducer 와 Global Reducer 에 모두 관여하게 됩니다.
이를 다르게 표현하면, (Partition 의 갯수 + 1 ) * Initial Value 만큼 결과값이 증가하게 됩니다.
Fold 여러 예시 확인해보기.
from pyspark import SparkConf, SparkContext conf = SparkConf().setAppName("test-parallelize") conf.setMaster('local[*]') conf.set("spark.driver.bindAddress", "localhost") sc = SparkContext(conf=conf) list_data = [1, 2, 3, 4, 5, 6] initial_value = 1 rdd = sc.parallelize(list_data, 1) output = rdd.fold(initial_value, lambda a, b: a + b) print(f'output: {output}') # output: 23 initial_value = 1 rdd = sc.parallelize(list_data, 2) output = rdd.fold(initial_value, lambda a, b: a + b) print(f'output: {output}') # output: 24 initial_value = 1 rdd = sc.parallelize(list_data, 3) output = rdd.fold(initial_value, lambda a, b: a + b) print(f'output: {output}') # output: 25 initial_value = 2 rdd = sc.parallelize(list_data, 3) output = rdd.fold(initial_value, lambda a, b: a + b) print(f'output: {output}') # output: 29 sc.stop()initial_value 1 & partition 1.
initial value 가 1 이고, Partition 이 1개인 경우에는 연산의 결과로써 23이 출력됩니다.
그 이유는 Partition 이 1개이기 때문에 Local Reducing 과정에서 Initial Value 가 한번 연산에 관여하고,
Global Reducing 단계에서 한번 관연하기 때문에 1 + 2 + 3 + 4 + 5 + 6 + 1 + 1 인 연산이 수행됩니다.
list_data = [1, 2, 3, 4, 5, 6] initial_value = 1 rdd = sc.parallelize(list_data, 1) output = rdd.fold(initial_value, lambda a, b: a + b) print(f'output: {output}') # output: 23initial_value 2 & partition 3.
initial value 가 2 이고, Partition 이 3개인 경우에는 연산의 결과로써 29 가 출력됩니다.
그 이유는 Partition 이 3개이기 때문에 Local Reducing 과정에서 Initial Value 가 3번 연산에 관여하고,
Global Reducing 단계에서 한번 관연하기 때문에 1 + 2 + 3 + 4 + 5 + 6 + 2 + 2 + 2 + 2 인 연산이 수행됩니다.
list_data = [1, 2, 3, 4, 5, 6] initial_value = 2 rdd = sc.parallelize(list_data, 3) output = rdd.fold(initial_value, lambda a, b: a + b) print(f'output: {output}') # output: 29반응형'Spark' 카테고리의 다른 글
[Spark] groupBy, RelationalGroupedDataset 알아보기 (0) 2024.01.26 [Spark] Union 알아보기 (0) 2024.01.26 [SparkSQL] CSV DataFrameReader 알아보기 (0) 2024.01.15 [Spark] Spark lit 알아보기 (0) 2023.12.24 Spark Stage 알아보기 (0) 2023.12.23