-
[Kafka] Partition Leader Election 알아보기 (파티션 리더 선출)Kafka 2023. 12. 31. 18:00728x90반응형

- 목차
함께 보면 좋은 글.
https://westlife0615.tistory.com/473
Kafka Controller Election 알아보기 ( Controller 는 어떻게 결정될까 ? )
- 목차 함께 보면 좋은 글. https://westlife0615.tistory.com/484 Zookeeper Znode 알아보기 - 목차 소개. Zookeeper 는 Znode 라는 데이터 저장기능이 존재합니다. Znode 는 데이터를 저장할 수 있는 논리적인 개념인
westlife0615.tistory.com
소개.
이번 글에서 카프카 클러스터에서 Partition Leader 가 어떻게 선출되는지에 대해서 알아보는 시간을 가지려고 합니다.
먼저 카프카의 구성요소들과 그들의 물리적 & 논리적인 관계에 대해서 알아보겠습니다.
카프카는 기본적으로 Broker, Topic, Partition 으로 구성됩니다.
Broker 는 카프카를 구성하는 물리적인 서버입니다.
Broker 들을 모여 카프카 클러스터를 구성합니다.
그리고 Topic 은 Kafka Message 를 묶는 논리적인 단위입니다.
카프카가 저장하고 관리하는 Kafka Message 들은 Topic 이라는 단위로 관리됩니다.
그리고 Topic 은 Partition 이라는 단위로 나뉘어집니다.
Partition 은 Log 와 Index 등으로 표현되는 물리적인 파일을 관리하는 단위인데요.
Partition 이 곧 Kafka Message 를 저장하는 물리적인 요소로 생각하셔도 무방합니다.
위에서 정리한 카프카의 구성요소들의 관계를 시각적으로 나타내어보면 아래와 같습니다.
첫번째 관계도.
<출처 : https://lankydan.dev/intro-to-kafka-topics-and-partitions>
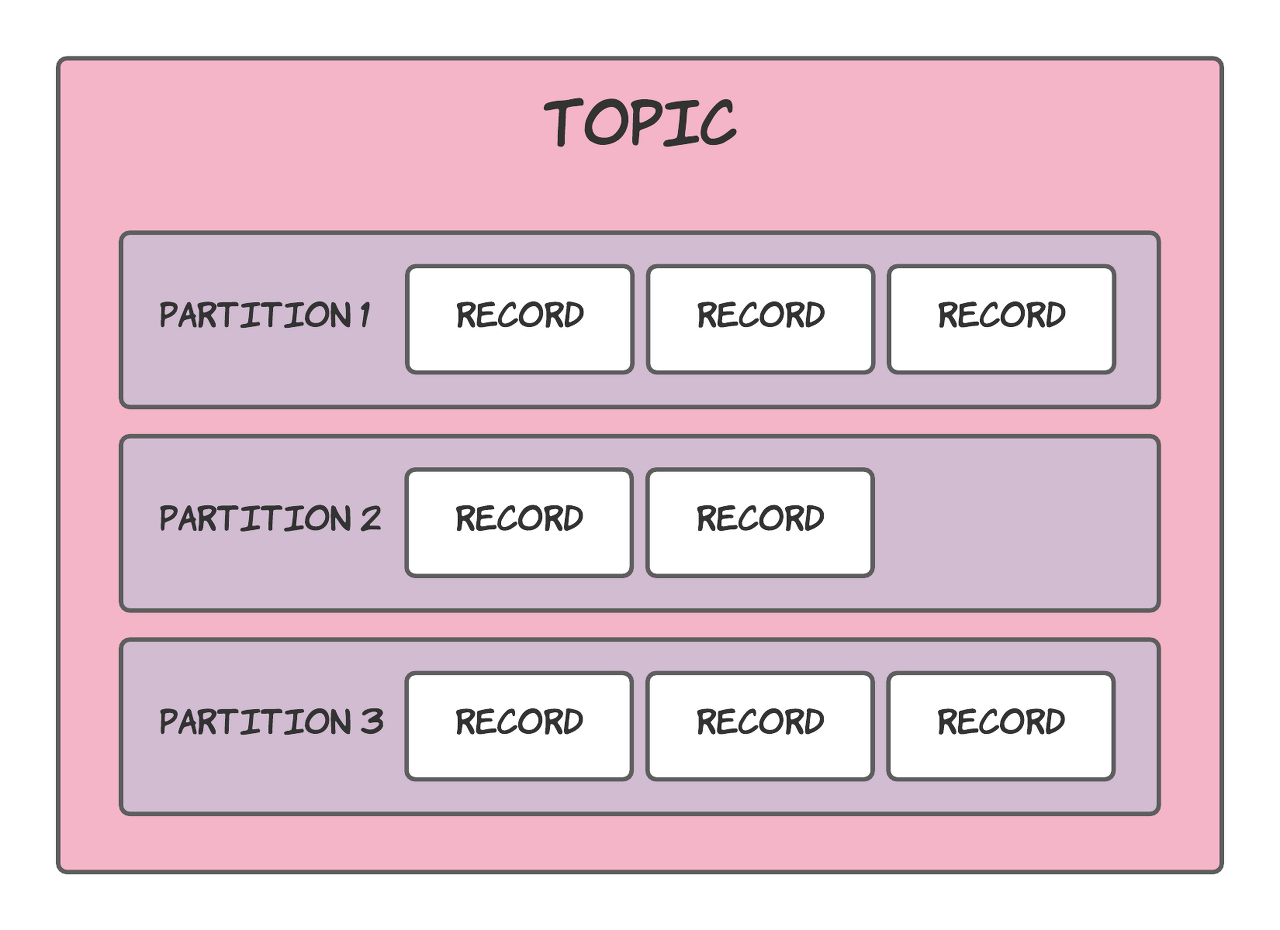
위 자료는 Topic 과 Partition 그리고 Record 의 관계를 보여주는 이미지입니다.
하나의 Topic 은 여러개의 Partition 들을 가질 수 있습니다.
위 케이스는 Topic 하나가 3개의 Partition 들을 가지고 있네요.
보통 3개의 Partition 이 하나의 Topic 을 구성하는 기본값으로 제공되고 있습니다.
그리고 Partition 이 Record 를 직접적으로 저장하고 관리하게 됩니다.
두번째 관계도.
< 출처 : https://www.conduktor.io/kafka/kafka-topics-choosing-the-replication-factor-and-partitions-count/>

위 자료는 Broker 와 Partition 그리고 Replication 에 대한 관계를 설명합니다.
위 케이스는 하나의 Topic 이 2개의 Partition 을 가지며, Replication 값은 3입니다.
그리고 3개의 Broker 들이 존재하네요.
Brokers : [ Broker 101, Broker 102, Broker 103 ] // 3개의 Broker 가 존재함. Topics : [ Topic 1 ] // 1개의 Topic 이 존재함. Topic 1 의 Partition : [ Partition 0, Partition 1 ] // 2개의 Partition 이 존재함.그리고 Replication 은 3이며 Replication 의 특성상
모든 Broker 에 Leader Partition 1개와 Replication Partition 2개가 고르게 분산됩니다.
이렇듯 Partition 의 종류는 Leader 와 Replicaion 으로 나뉘게 되며,
Replication Partition 은 Kafka Message 의 복제에 집중하게 됩니다.
그리고 Leader Partition 을 가지는 Broker 가 Partition Leader 가 되죠.
이어지는 글에서 Partition Leader Election 에 대한 자세한 설명을 이어나가겠습니다.
Partition Leader Election.
카프카 클러스터는 Controller 라는 Leader Broker 가 존재합니다.
Controller 는 Leader Broker 로써 다른 Broker 들을 관리하게 됩니다.
Controller 의 역할들 중의 하나가 Partition Leader Election 입니다.
Controller는 Kafka Cluster 내부의 Broker 들 중에서 적절한 Broker 를 찾아
이 Broker 를 특정 Partition 의 Leader 로 선출하게 됩니다.
Partition Leader Election 과정은 아래와 같습니다.
참고로 3개의 Broker 로 구성된 Kafka Cluster 환경에서 설정을 진행합니다.
그리고 1번 Broker 가 Controller 인 상태입니다.
1. Topic 생성.
먼저 Topic 을 생성합니다.
Partition 과 Replication 은 각각 3으로 설정하였습니다.

Znode 는 아래와 같이 생성됩니다.
/brokers/topics /brokers/topics/test_topic /brokers/topics/test_topic/partitions /brokers/topics/test_topic/partitions/0 /brokers/topics/test_topic/partitions/1 /brokers/topics/test_topic/partitions/2 /brokers/topics/test_topic/partitions/0/state /brokers/topics/test_topic/partitions/1/state /brokers/topics/test_topic/partitions/2/state2. Controller 는 Broker 들에게 Partition Assignment 정보를 전달함.
Controller 는 여러가지 규칙에 의거하여 Partition 와 Broker 의 관계를 결정합니다.
2번 Broker 에게 전달되는 Event 입니다.
Event 의 내용은 3개의 Partition 에 대해서 2번 Broker 의 역할에 대한 내용입니다.
UpdateMetadataPartitionState( topicName='test_topic', partitionIndex=2, controllerEpoch=1, leader=1, leaderEpoch=0, isr=[1, 2, 3], zkVersion=0, replicas=[1, 2, 3], offlineReplicas=[] ) // test_topic 의 2번 Partition 에 대해서 Leader 는 1번 브로커이고 // 2번 브로커인 자신은 Replication 의 역할을 수행해야함. UpdateMetadataPartitionState( topicName='test_topic', partitionIndex=1, controllerEpoch=1, leader=3, leaderEpoch=0, isr=[3, 1, 2], zkVersion=0, replicas=[3, 1, 2], offlineReplicas=[] ) // test_topic 의 1번 Partition 에 대해서 Leader 는 3번 브로커이고 // 2번 브로커인 자신은 Replication 의 역할을 수행해야함. UpdateMetadataPartitionState( topicName='test_topic', partitionIndex=0, controllerEpoch=1, leader=2, leaderEpoch=0, isr=[2, 3, 1], zkVersion=0, replicas=[2, 3, 1], offlineReplicas=[] ) // test_topic 의 0번 Partition 에 대해서 Leader 는 2번 브로커인 자신임.3번 Broker 또한 같은 내용의 UpdateMetadataPartitionState Event 를 전달받습니다.
Broker 들은 Controller 로부터 전달받는 위와 같은 정보를 기반으로
Topic & Partition 과 관련된 Znode 에 Watcher 로써 동작할 수 있게 됩니다.
Broker 가 종료되는 경우의 Leader Election.
3번 Broker 가 종료됩니다.
3번 Broker 는 "test_topic" Topic 의 1번 Partition 의 Leader 였는데요.
3번 Broker 가 종료됨으로써 Controller 인 1번 Broker 또는 2번 Broker 가 1번 Partition 의 새로운 Leader 가 되어야합니다.
결과는 아래 이미지와 같이 Controller 인 1번 Broker 가 1번 Partition 의 새로운 Leader 가 됩니다.

그리고 3번 Broker 가 재시작하게 된 이후에는
다시 3번 Broker 는 1번 Partition 의 Leader 가 됩니다.

Broker 가 추가되는 경우.
새로운 Broker 가 추가되는 경우의 Partition Leader 는 어떻게 될까요 ?
새로운 Broker 를 추가한 이후에 Partition Leader 를 종료해보겠습니다.
4번 Broker 를 새롭게 생성한 이후에 Kafka Cluster 에 추가합니다.
Kafka Cluster 의 구성은 아래와 같아집니다.

그리고 3번 Broker 를 종료하도록 하겠습니다.
그리고 아래의 명령어를 통해서 Repartitioning 을 시도해보겠습니다.
종료된 3번 Broker 를 4번 Broker 가 대체하게 됩니다.
cat <<EOF> /tmp/repartition.json { "version": 1, "partitions": [ {"topic": "test_topic", "partition": 0, "replicas": [2, 4, 1], "leader": 2}, {"topic": "test_topic", "partition": 1, "replicas": [4, 1, 2], "leader": 4}, {"topic": "test_topic", "partition": 2, "replicas": [1, 2, 4], "leader": 1} ] } EOF kafka-reassign-partitions --bootstrap-server localhost:9092 \ --reassignment-json-file /tmp/repartition.json --execute 반응형
반응형'Kafka' 카테고리의 다른 글
[Kafka] Log Index File 알아보기 (0) 2024.01.03 [Kafka] listeners, advertised.listeners 알아보기 (2) 2024.01.01 [Kafka Streams] Config 알아보기 (0) 2023.12.29 Kafka Log Segment 알아보기 (0) 2023.12.25 [Kafka] Zookeeper 는 Broker 를 어떻게 관리할까 ? (0) 2023.12.22